
KubeCon Copenhagen 2018 - Day 2

NOTE
All credit for the slides in the pictures goes to their creators!
NOTE
If you are in one of these pictures and want it removed, please contact me by email (see about/imprint page).
WIP This post is still work in progress! The content of this post can rapidly change. This note will be removed when the post has been completed.
Welcome!
A warm "Welcome" if you are new to the three day post series from KubeCon Copenhagen, I recommend you to checkout the first day blog post too, here KubeCon Copenhagen 2018 Day 1.
Morning Keynotes
Keynote: Kubernetes Project Update - Aparna Sinha, Group Product Manager, Kubernetes and Google Kubernetes Engine, Google
Kubernetes Major Milestones
The following points are currently especially important for enterprises:
- Security
- Applications
- Experience
Security

On GKE they made updates seamless. "Old" points are awaking for Kubernetes like Threat detection. GKE integrates with a good amount of security/treat detections to make the platform safer. Upcoming from SIG container is sandboxed containers. To get a "full" sandboxed container, you should use a hypervisor. Still the users want the low resource point of (normal) containers. Google has open sourced gVisor which is a sandboxed container runtime.

Applications

Kubernetes has now an integration to be the scheduler for Apache Spark. To automate stateful applications, it is recommended to use an operator.

In the demo Google's spark-operator was showcased. I recommend to checkout the recording, to see exactly what she showed.
Monitoring

Prometheus is the default monitoring/metrics pipeline in Kubernetes.
Developer Experience
A Google Customer engineer developed Skaffold which improves the developer experience for continuous integration + deployment. In the end the developer just wants to "run his code". The important part is that the developer can focus on the development. Skaffold will pick up changes and automatically deploy it to Kubernetes (from what I think, especially for testing).
Keynote: Accelerating Kubernetes Native Applications - Brandon Philips, CTO of CoreOS, Red Hat
The point of operators making it easy to deploy and manage applications is more and more important.

It is amazing to hear a success story such as that for an operator, as you normally just hear "it works" ;)

They will release more components of the operator framework over the coming weeks. But a point coming with with having more and more operators running is that you need a lifecycle management for operators in general. A lifecycle management in that point could be like a catalog of operators.
Keynote: Switching Horses Midstream: The Challenges of Migrating 150+ Microservices to Kubernetes - Sarah Wells, Technical Director for Operations and Reliability, Financial Times
If you are doing a thing such as "live" migration, it is as with every project a journey.

Their setup is very complex as they went completely for microservice architecture already. They see innovation like a spending (innovation token). In the end they reached a cost reduction in AWS of about ~80%.

They opted for Kubernetes, so they can ask other people about it as opposed to creating their own orchestration tool. With an own tool, you on your own need to know the documentation.
"You pay a cost when running services in parallel" - Sarah Wells
It is always a risk, but risks are to be conquered if the advantages overweight the disadvantages. They used traffic replay to test further and simply use their existing API to push to both stacks to test.
"Switching from systemd files to Helm" - Sarah Wells
If you don't use Golang vendoring, you're gonna have a bad time when rebuilding a two year old project.

In their case they had a good amount of services already having a readiness and/or liveness "interface".
"Easy to get sucked into making things better" - Sarah Wells
"It is worth mentioning the increase in bills to the people that pay the bills" - Sarah Wells
The final migration went smooth for them mostly only issues arose because people used the platform in a way they didn't understand.

They broke even in about three years after their migration.
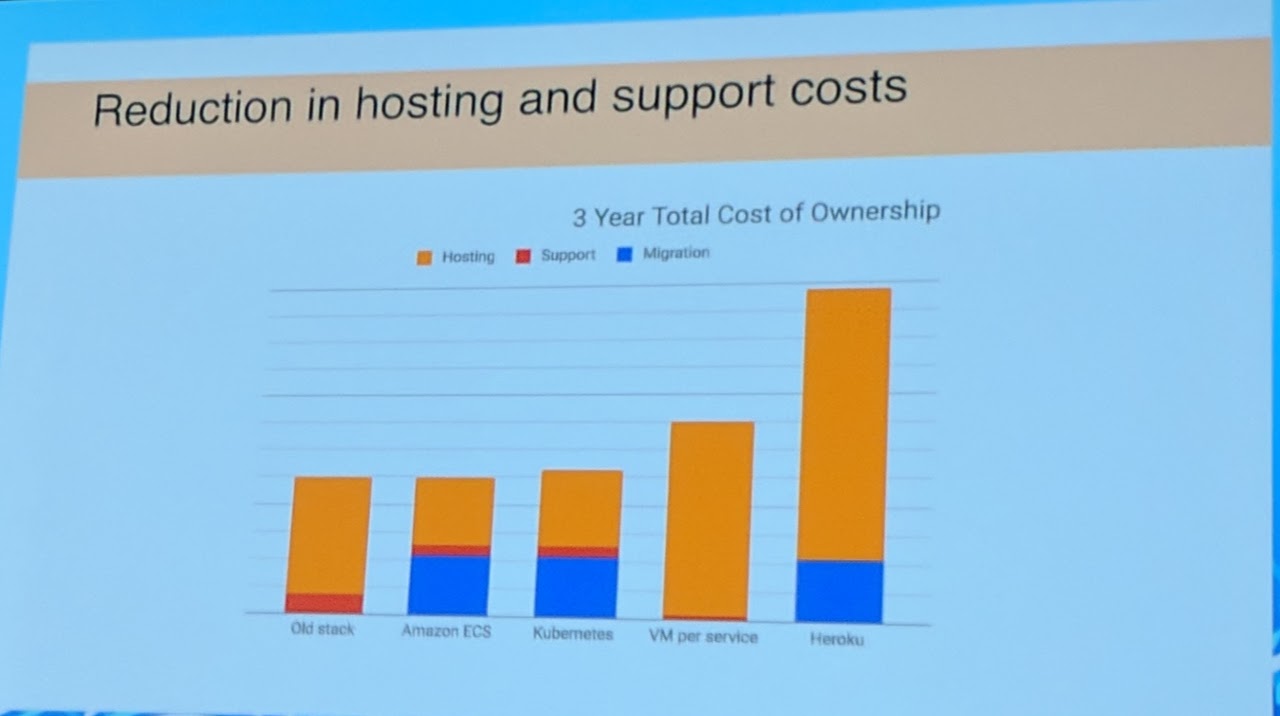
"...a happier team..." - Sarah Wells
Keynote: Shaping the Cloud Native Future - Abby Kearns, Executive Director, Cloud Foundry Foundation

Everything is "cobbling" together a way for themselves to the cloud.
 Trinity of Interoperability, Innovation and Velocity
Trinity of Interoperability, Innovation and Velocity
A companies world increases with each software/technology they use.
TBH this is kind of the same as everyone is saying:
- OpenSource is cool
- We have to get together (conferences, meetups, etc)
- And so on..
Keynote: Skip the Anxiety Attack - Build Secure Apps with Kubernetes, Jason McGee, Fellow, IBM
I wasn't at the keynote because I had checked out the CNCF booth for the "Meet the Maintainer - Rook" meetup.
Keynote: Software's Community - Dave Zolotusky, Software Engineer, Spotify
I wasn't at the keynote because I had checked out the CNCF booth for the "Meet the Maintainer - Rook" meetup.
Meet the Maintainer - Rook
Hostile takeover of the @CloudNativeFdn booth in progress #kubecon pic.twitter.com/B034FWvOgk
— rook (@rook_io) May 3, 2018
It was nice meeting people interested in Rook.
Talks
Blackholes and Wormholes: Understand and Troubleshoot the “Magic” of Kubernetes Networking - Minhan Xia & Rohit Ramkumar, Google (Intermediate Skill Level)
Both talkers are "the last line of defense" for support cases.
Blackhole Case
No backend receives a packet sent by another Pod after a endpoint change.

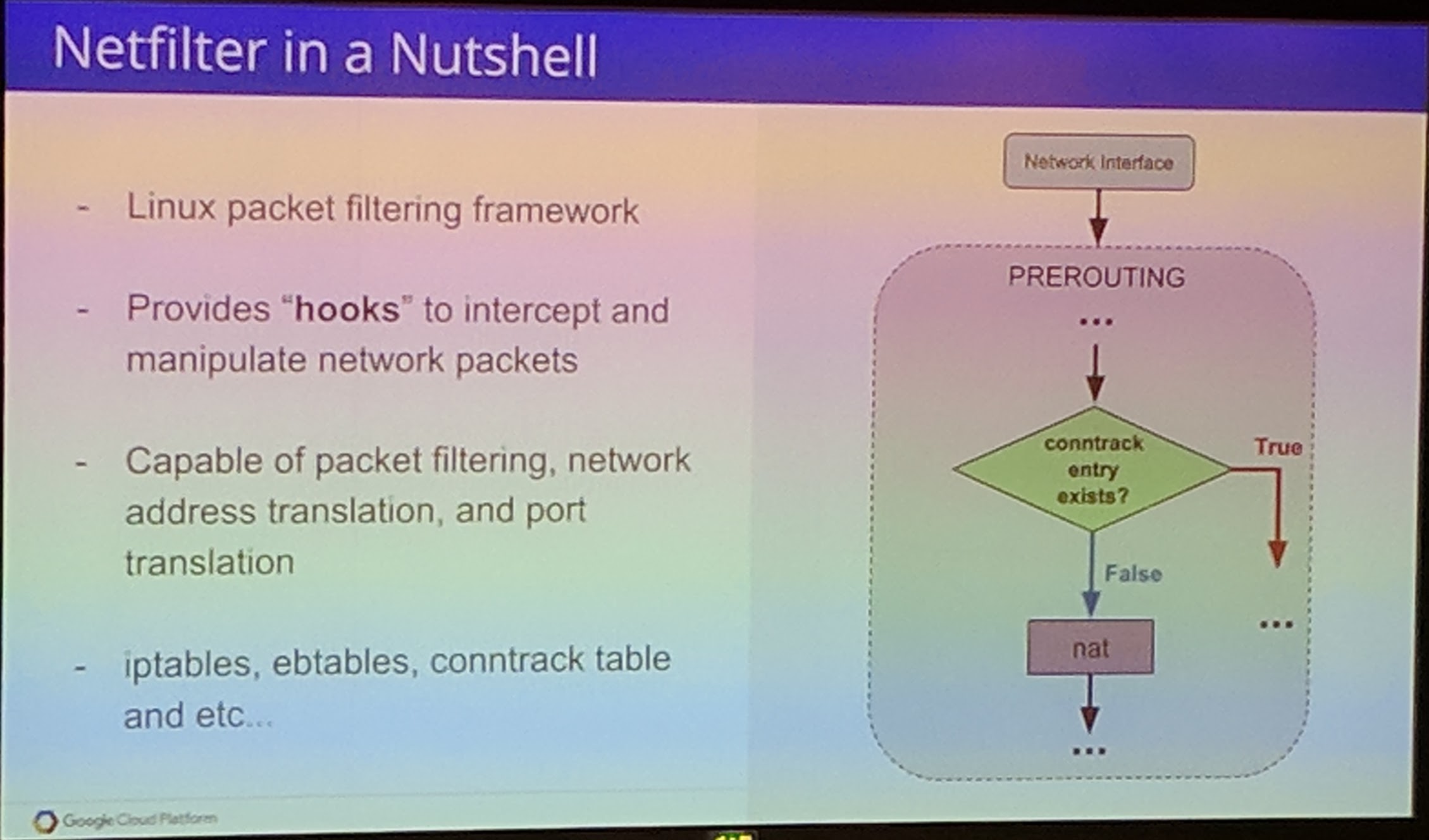
In this case, when the Service IP is called a conntrack entry is created when routed to Pod A. When a Pod is killed and the conntrack entries still exist, the traffic fails to get to the other Pods because of this. A fix for this has been implemented in kube-proxy. Kube-proxy flushes the conntrack table of stale entries now, though there might be a small delay/loss for then incoming packets until "everything" has been refreshed.
Yet Another Blackhole Case

This was caused due to OOM causing networkd to be restarted which then triggered a bug that reset the forwarding sysctl setting for the main ethernet interface to 0 causing no more traffic to be forwarded to the container network bridge.
Wormhole
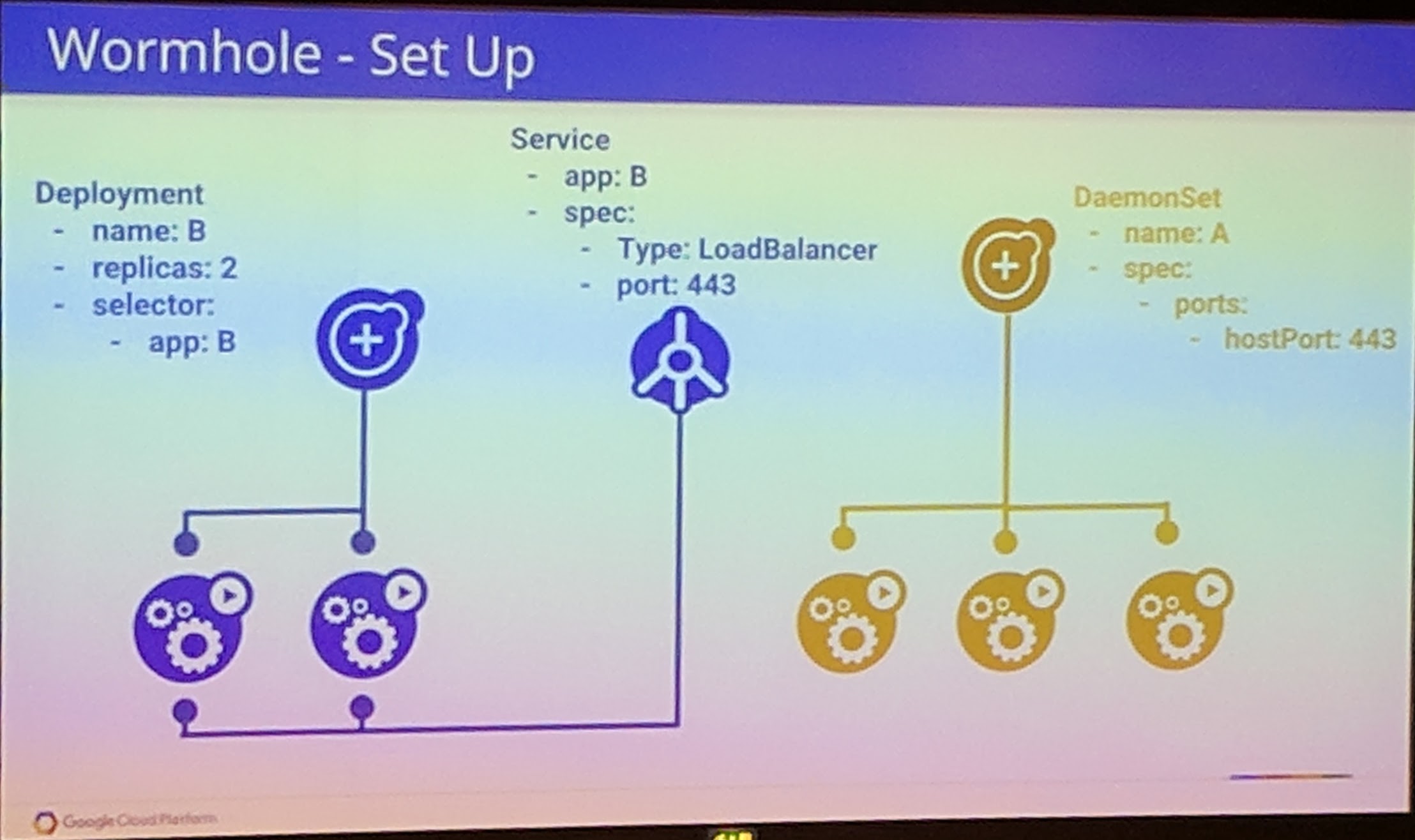
Because of Pod B on a node which exposes a hostPort that is the same as the Pod A, that is why the traffic is wormholed to Pod B.
"Iptables should be as explicit as possible." - Minhan Xia & Rohit Ramkumar
Troubleshooting
Iptables is the first source of truth.

Each endpoint has it's own chain.
conntrack is also an important to see where the connection got "tracked" to.
tcpdump should be used to verify that a request/data was actually sent from a Pod and/or received on another node.

Clusters as Cattle: How to Seamlessly Migrate Apps across Kubernetes Clusters - Andy Goldstein, Heptio (Intermediate Skill Level)

"Tickets Approvals Delays" - Andy Goldstein
Your server is your pet, when it is broken you want to fix it as fast as possible.
Kubernetes does the scheduling.
"Is a cluster a cattle or a pet?" - Andy Goldstein

"At one point every node will be decomissioned" - Andy Goldstein
Overall in Kubernetes yout should not use IPs for Services. DNS names should be used instead.
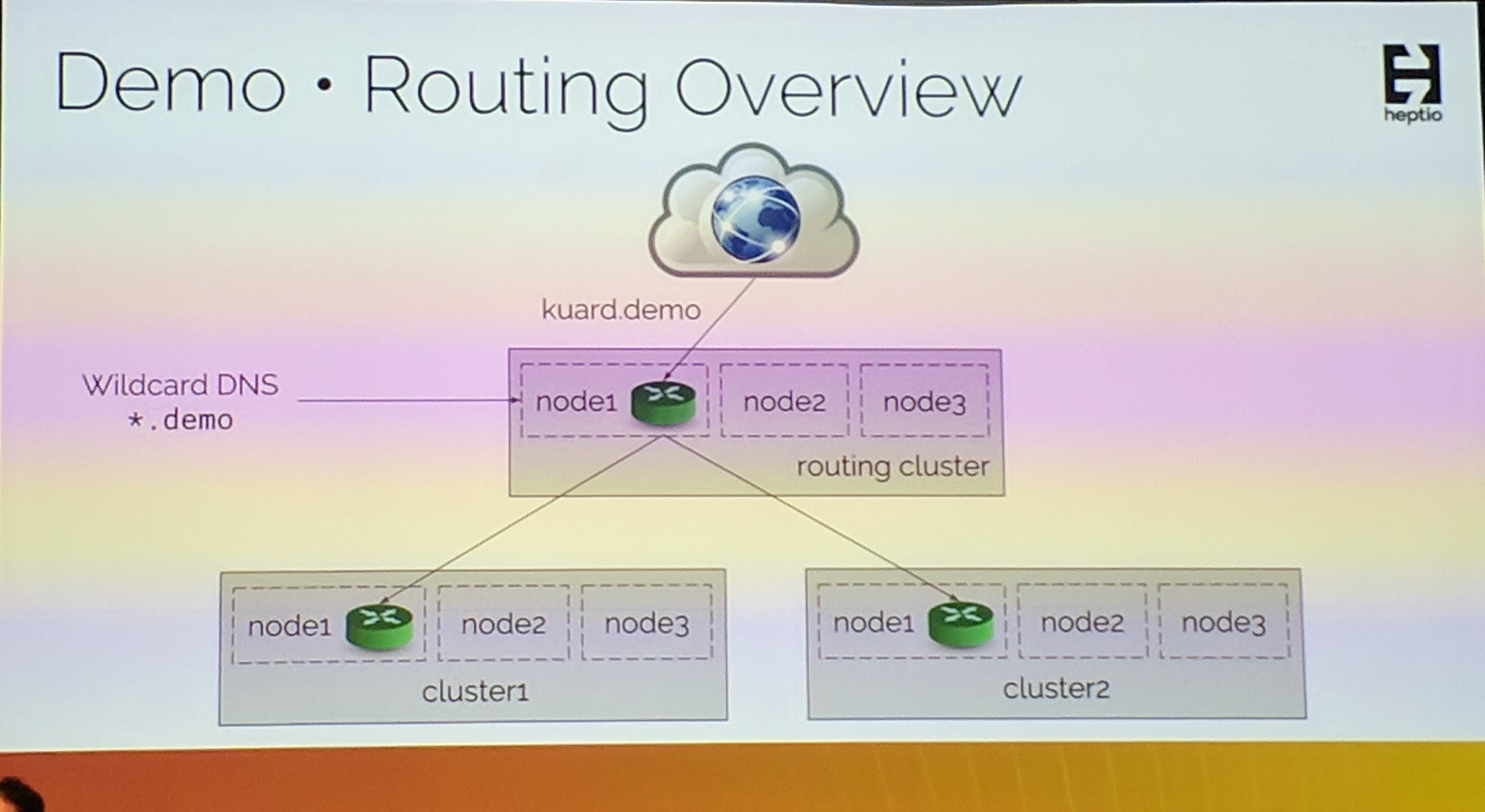
When migrating one could potentially use a setup such as this and use a separate Kubernetes cluster to do the routing of the internet traffic.
His demo showed the whole setup he explained. He showcased the migration point from one to another cluster. This can potentially be also used for failover. Additionally to that heptio/ark's backup and restore was demonstrated with that.
Interesting to see the switch functionality between the clusters with a simple config change.
All Attendee Party
 So many people!
So many people!
The @CloudNativeFdn has stepped up their game. This event rocks! A new normal for #kubecon pic.twitter.com/hprNrJnK5V
— bassam (@bassamtabbara) May 3, 2018
Summary
The all attendee party was awesome! Looking forward to the next KubeCon all attendee party already.
Have Fun!