
KubeCon Copenhagen 2018 - Day 1

NOTE
All credit for the slides in the pictures goes to their creators!
NOTE
If you are in one of these pictures and want it removed, please contact me by email (see about/imprint page).
WIP This post is still work in progress! The content of this post can rapidly change. This note will be removed when the post has been completed.
Welcome!
A big welcome to everyone at KubeCon! I'm happy to have already met a good amount of Rooklers just during badge pickup.
Morning Keynotes
Keynote: How Good Is Our Code? - Dan Kohn, Executive Director, Cloud Native Computing Foundation
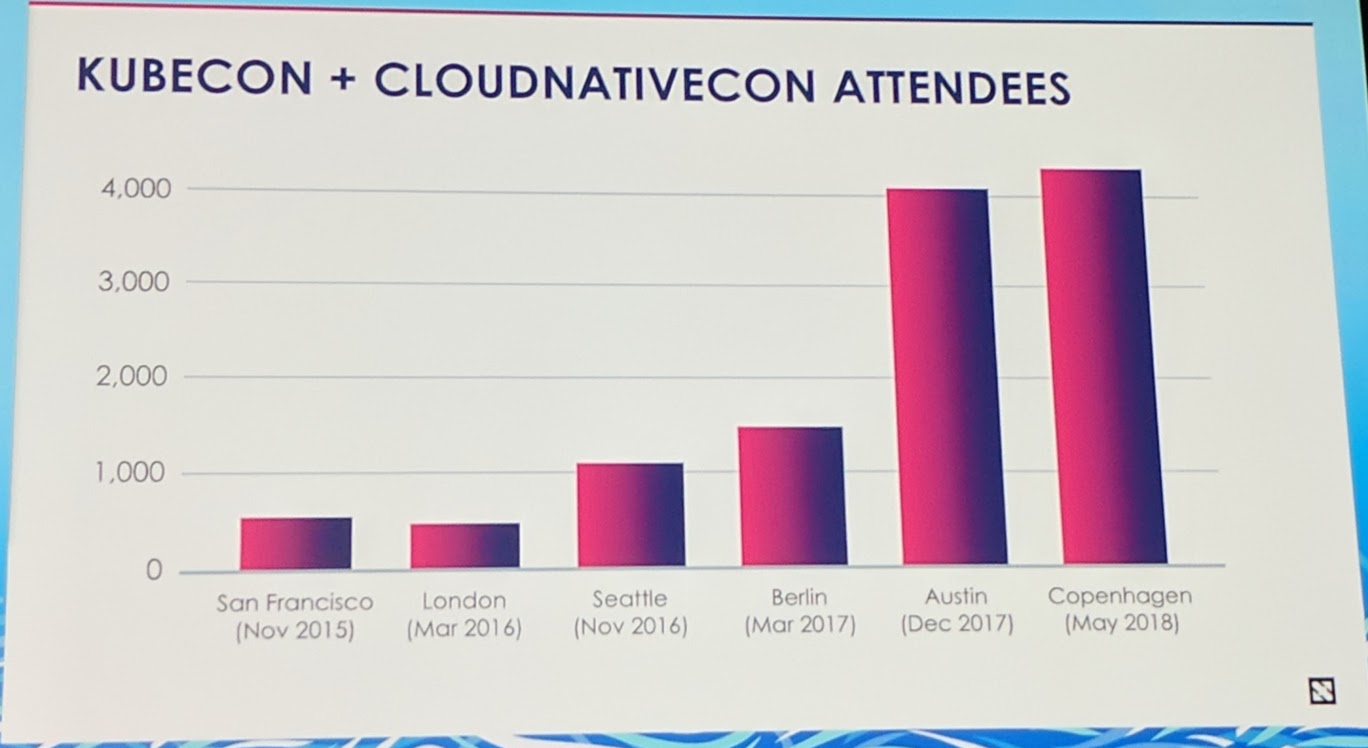

SQLite is a good example for test coverage, because they have 100% coverage. But even though they have a test coverage of 100%, bugs have been found with a "magic" genetic bug finder program. Bugs in such a case are hopefully just caused by usages that the developers hasn't thought about and because of that has not tested for.
 (SLOCs are lines of code)
(SLOCs are lines of code)
"A patch doesn't help until it is deployed to production" (Continous Integration) - Dan Kohn
CI should run multiple types of tests, smoke, integration, unit. As Kelsey Hightwoer wrote in a tweet, if you don't have CI for your application, Kubernetes is your smallest problem.
A cloud native trail map is available at the CNCF sponsor showcase booth or online at l.cncf.io. Your adventure though should first lead to containers of your applications, because containerized CI is easier to do.
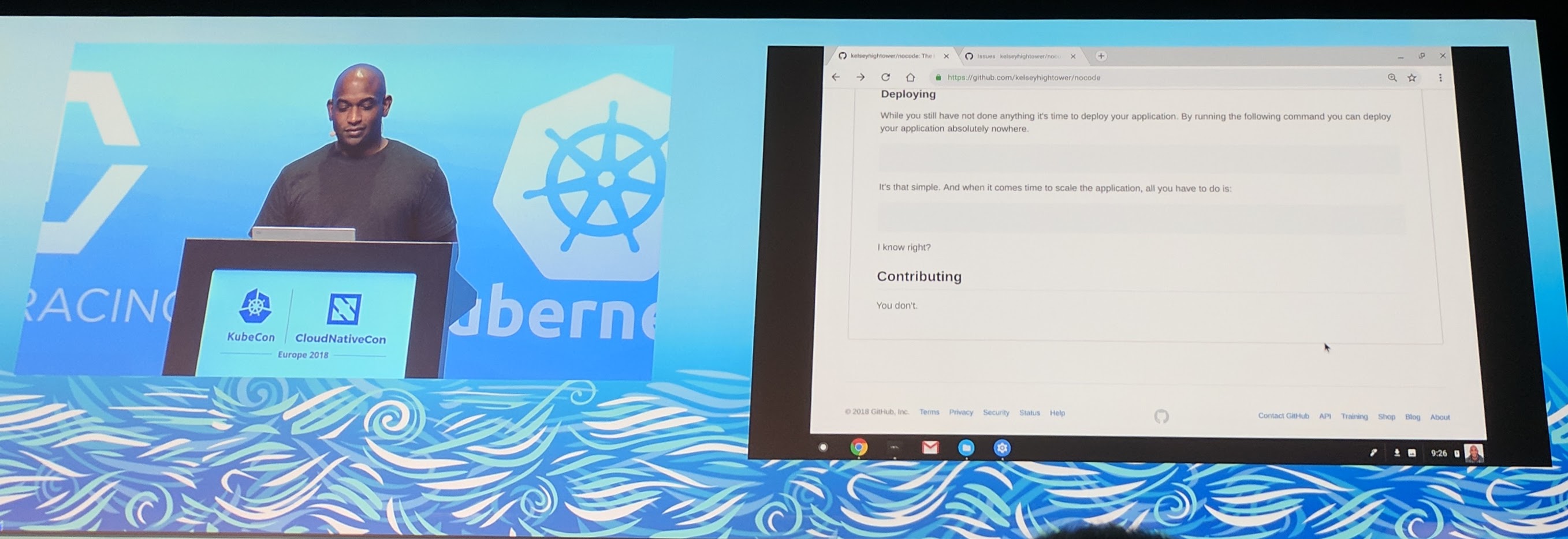
Kelsey Hightwoer showed his GitHub kelseyhightwoer/nocode "tutorial". It was hilarious, definitely checkout the keynote recording for that.
Keynote: CNCF Project Update - Liz Rice, Technology Evangelist, Aqua Security; Sugu Sougoumarane, CTO, PlanetScale Data; Colin Sullivan, Product Manager, Synadia Communications, Inc. & Andrew Jessup, Co-founder Scytale Inc.
Currently there is a total of 20 projects in the CNCF.
Sandbox projects
 (FTW! I'm totatlly not biased;))
(FTW! I'm totatlly not biased;))
- Rook
- Open Policy Agent
- SPIFFE & SPIRE - Tries to solve the problem of trust between workloads. Looks interesting to clear up the authentication/trust issues currently broadly existing.
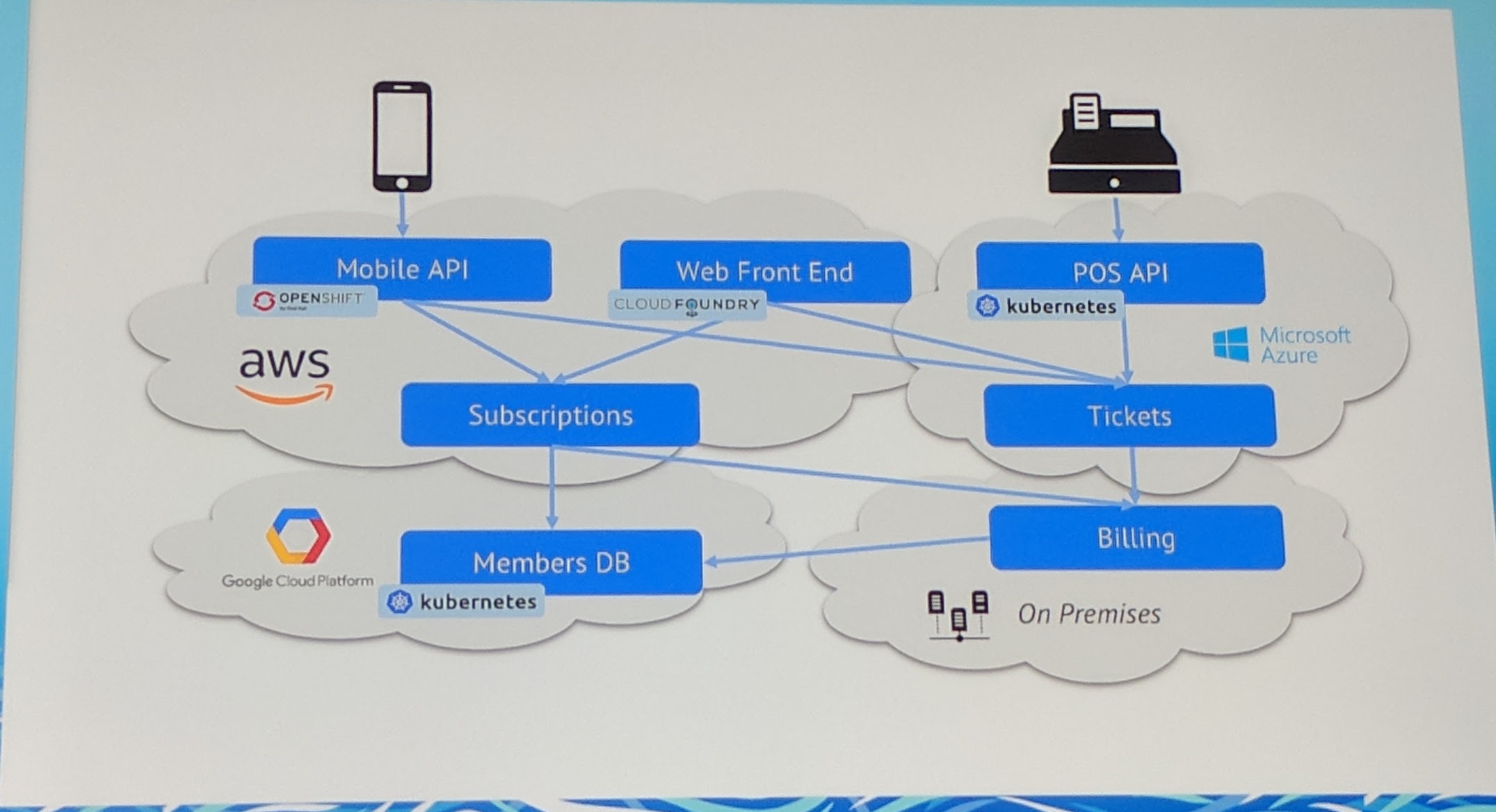 In a multi cloud world, who is establishing the trust?
In a multi cloud world, who is establishing the trust?
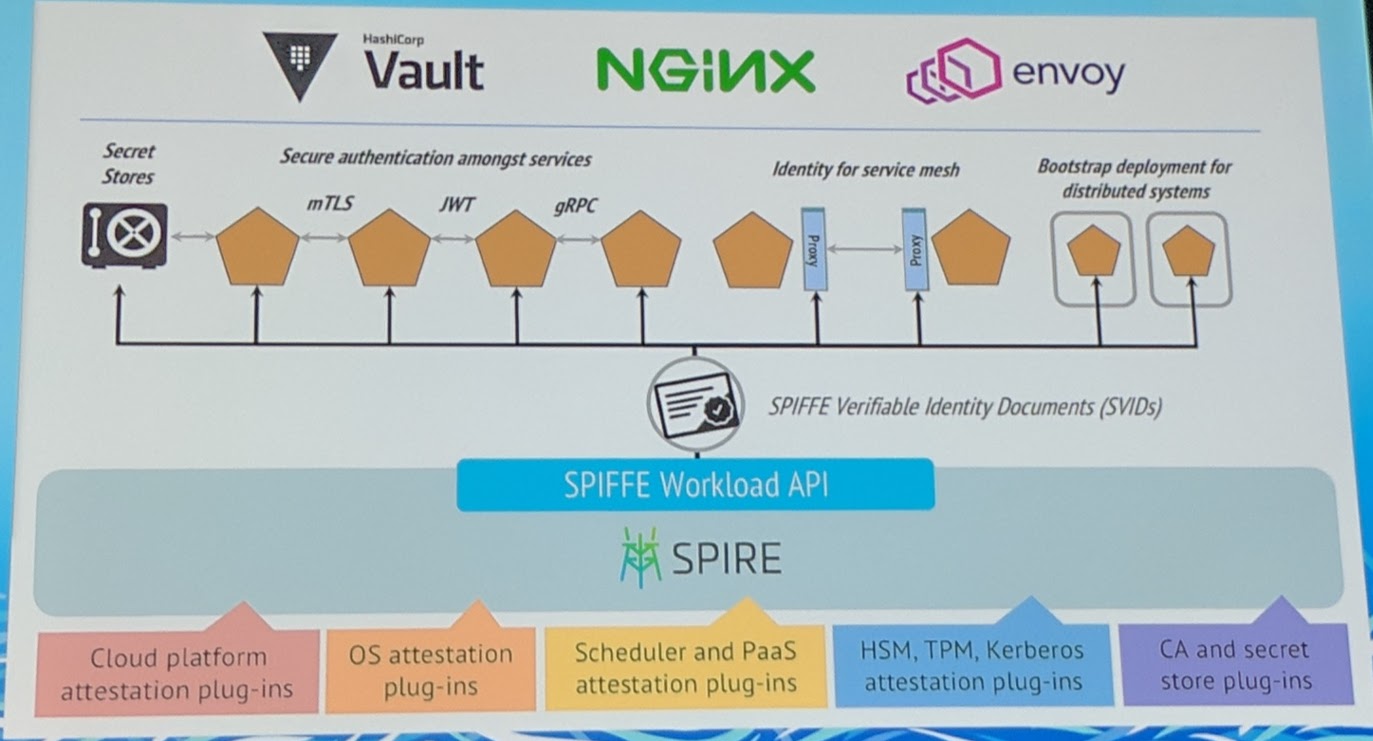 SPIFFE & SPIRE can be a solution to improve the situation
SPIFFE & SPIRE can be a solution to improve the situation
Incubation projects
- coreDNS
- Linkerd
- Envoy
- Prometheus
- OpenTracing (Updated APIs and libraries for a total of 9 languages)
- Jaeger
- Fluentd
- NATS - Already has some CNCF Projects integration, like Prometheus
- Container Network Interface (CNI)
- GRPC
- containerd (v1.1 Support for Kubernetes CRI)
- TUF (Secure framework for software updates)
- Notary (based on TUF, for secure software distribution)
- Vitess (database orchestration for MySQL horizontal scaling, takes away the pain of sharding in the application)
 NATS feature list
NATS feature list
Vitess showed an interesting demo:
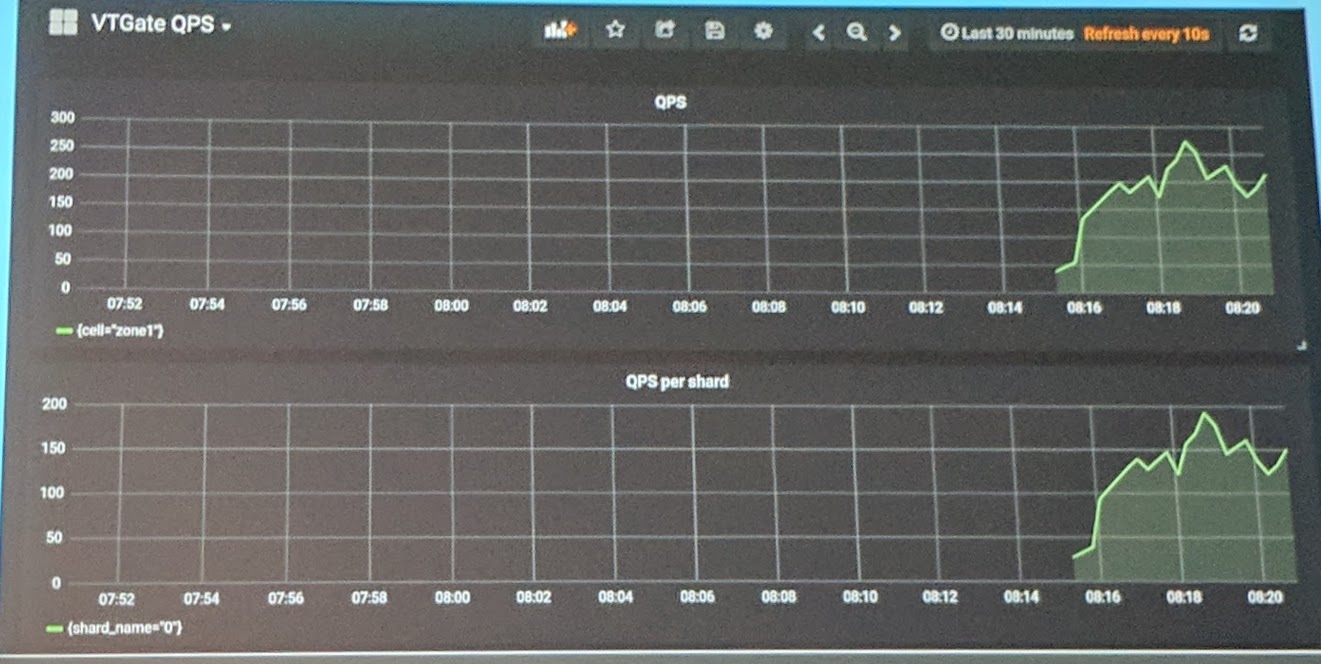 Grafana dashboard showing the Vitess Gateway QPS and other metrics
Grafana dashboard showing the Vitess Gateway QPS and other metrics
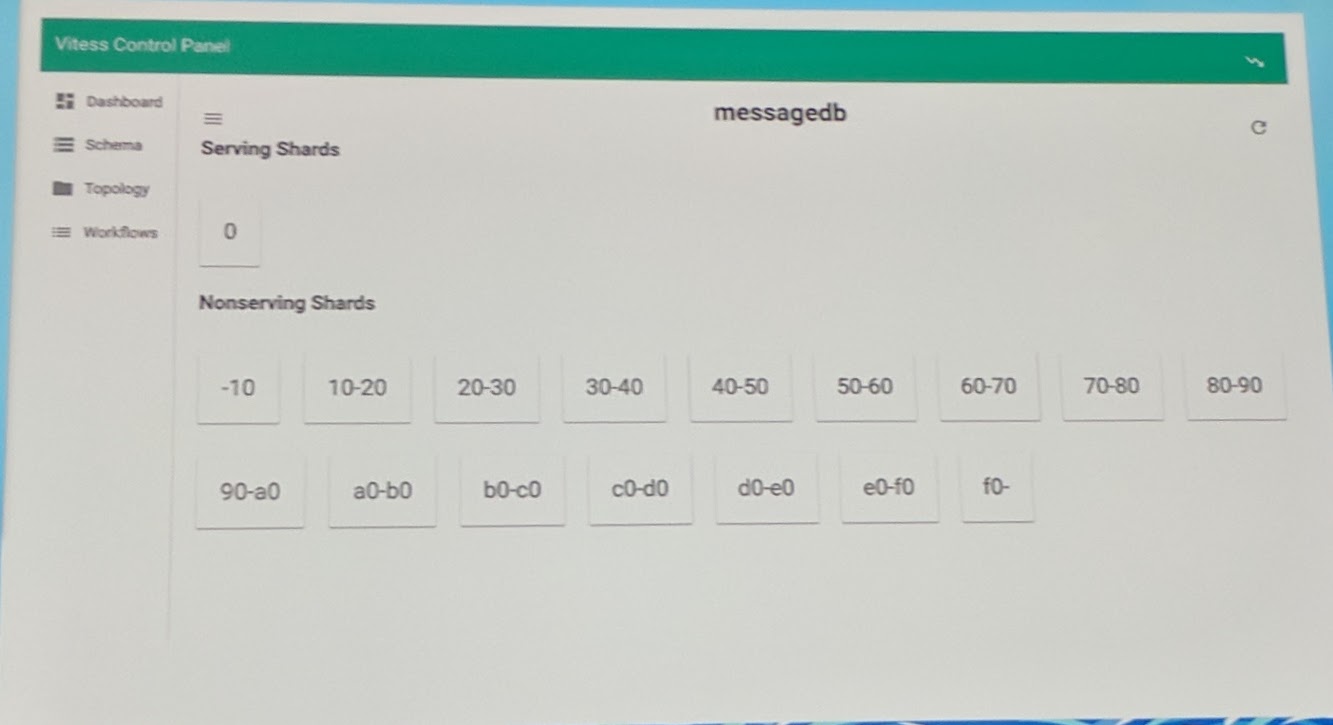 Vitess webinterface before telling Vitess to use the shards
Vitess webinterface before telling Vitess to use the shards
It is easy and awesome looking! They have a simple to use cli tool to execute tasks, but it seems that everything is managed through Kubernetes.
Graduated Projects
Kubernetes is the first project that has graduated.
What is graduation?
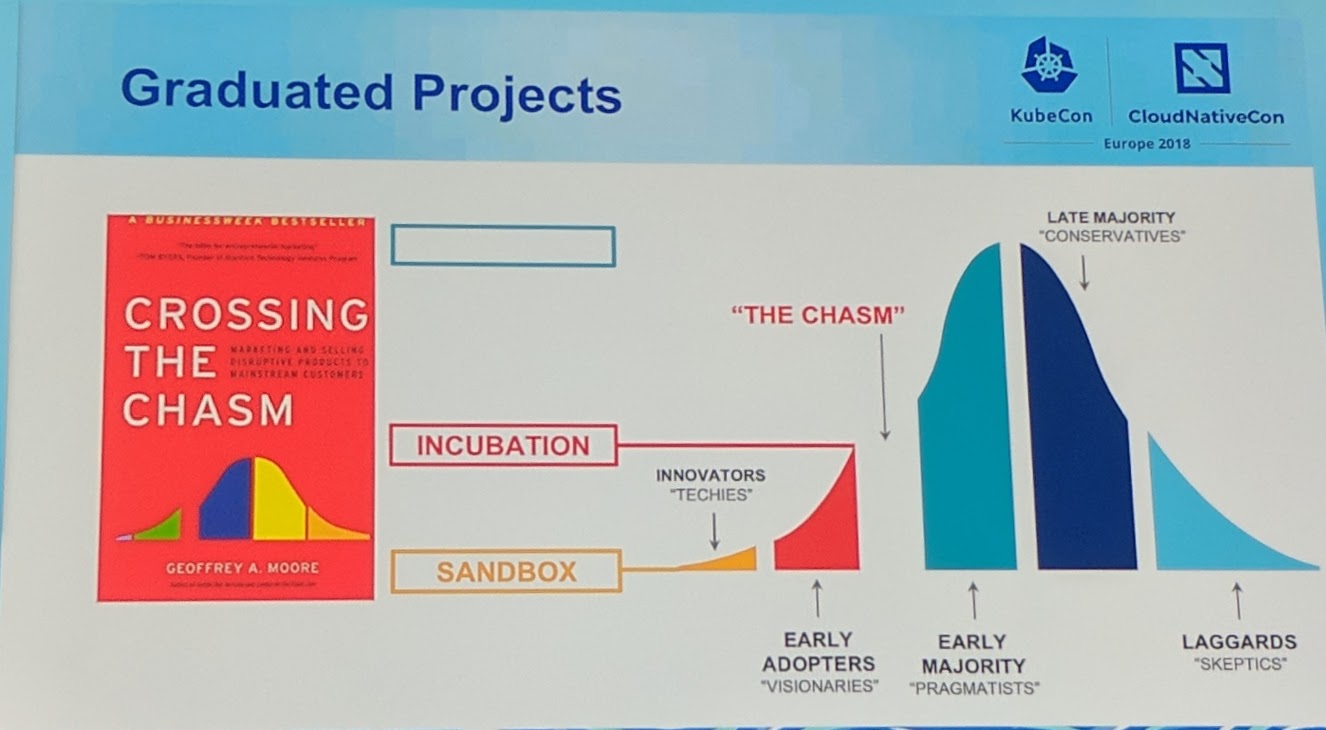 Graduation 'graph'
Graduation 'graph'
Getting involved into CNCF projects
Track sessions about "nuts and bolts" of projects/implementations- Intros & Deep Dives of the Projects, Kubernetes SIG and CNCF working groups. Hallway Track to meet people in the hallway to find out about others problems and solutions.
You are the community!
Keynote: Re-thinking Networking for Microservices - Lew Tucker, VP/CTO Cloud Computing, Cisco Systems, Inc.
Cisco has created "Cisco Container Platform".
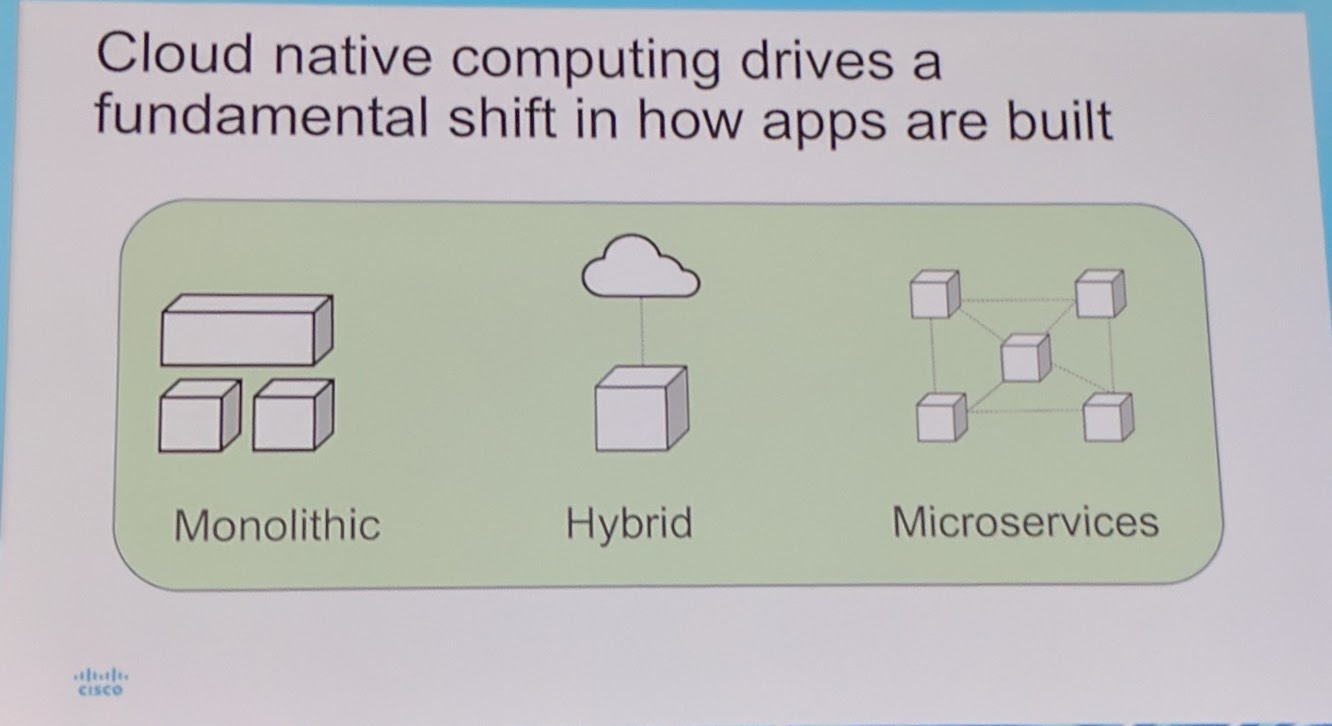 There is a shift in how apps are built.
There is a shift in how apps are built.
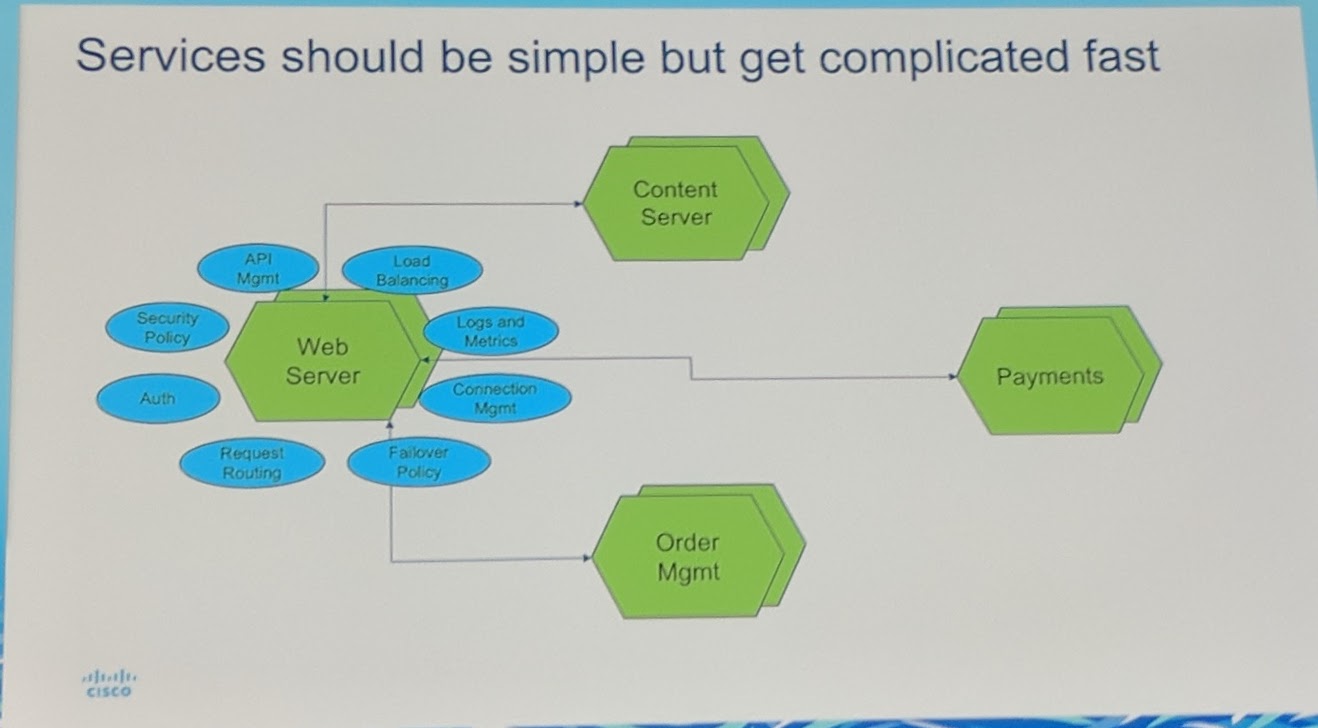 'Services should be simple but get complicated fast'
'Services should be simple but get complicated fast'
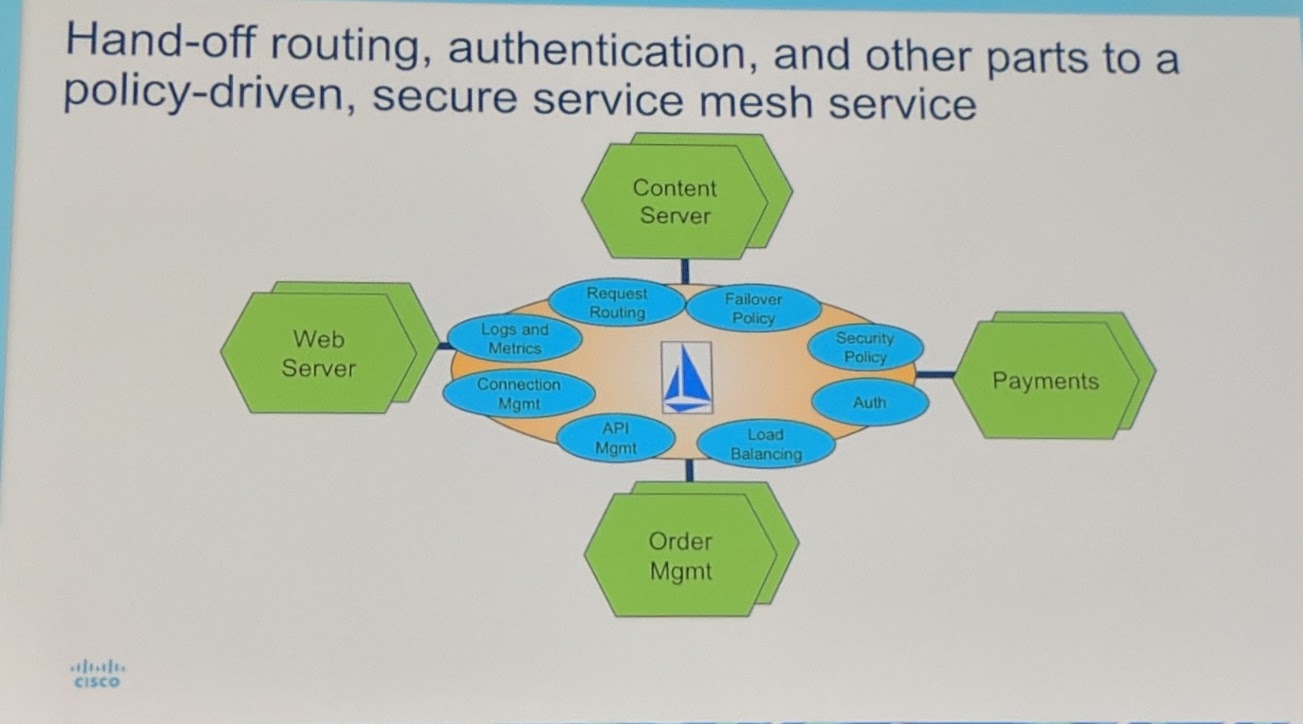 Handing-off certain tasks to a service mesh.
Handing-off certain tasks to a service mesh.
Using a service mesh allows to not modify the service's code to get it more "secure".
Keynote: CERN Experiences with Multi-Cloud Federated Kubernetes - Ricardo Rocha, Staff Member, CERN & Clenimar Filemon, Software Engineer, Federal University of Campina Grande
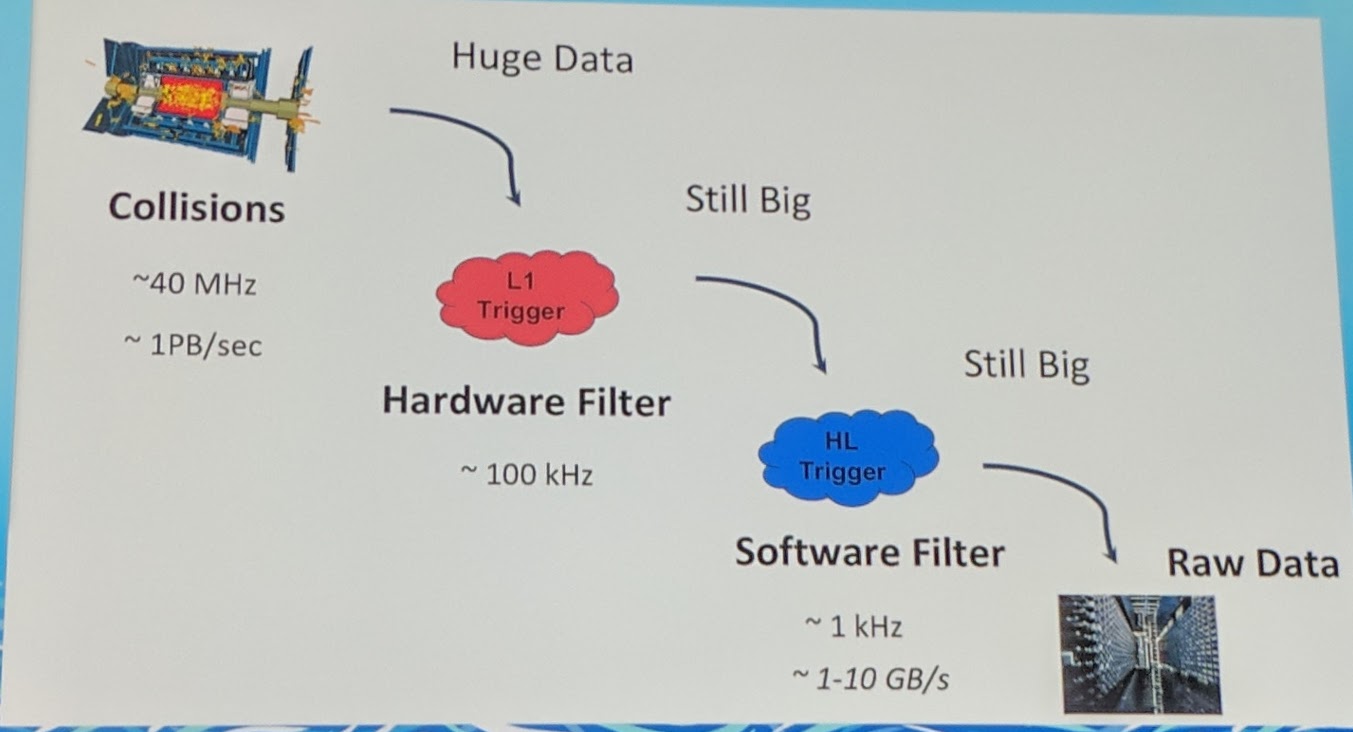
They have a lot of data up to 1PB/sec, but it is filtered and in the end it can be about 1-10GB/s. Over 200 Kubernetes are already running, from small to large clusters.

Their numbers are extremely high in comparison to some big companies.
Their motivation for Federation is the uniform API for deployments, load balancing and much more. It is especially good for their use cases with batch jobs, done with HTCondur. HTCondur allows for good scheduling by taking fair share and preemption into account. But HTCondur needs external storage and networking. They have containerized the whole thing and use the Kubernetes Federation on "all" of their clusters dedicated to HTCondur.
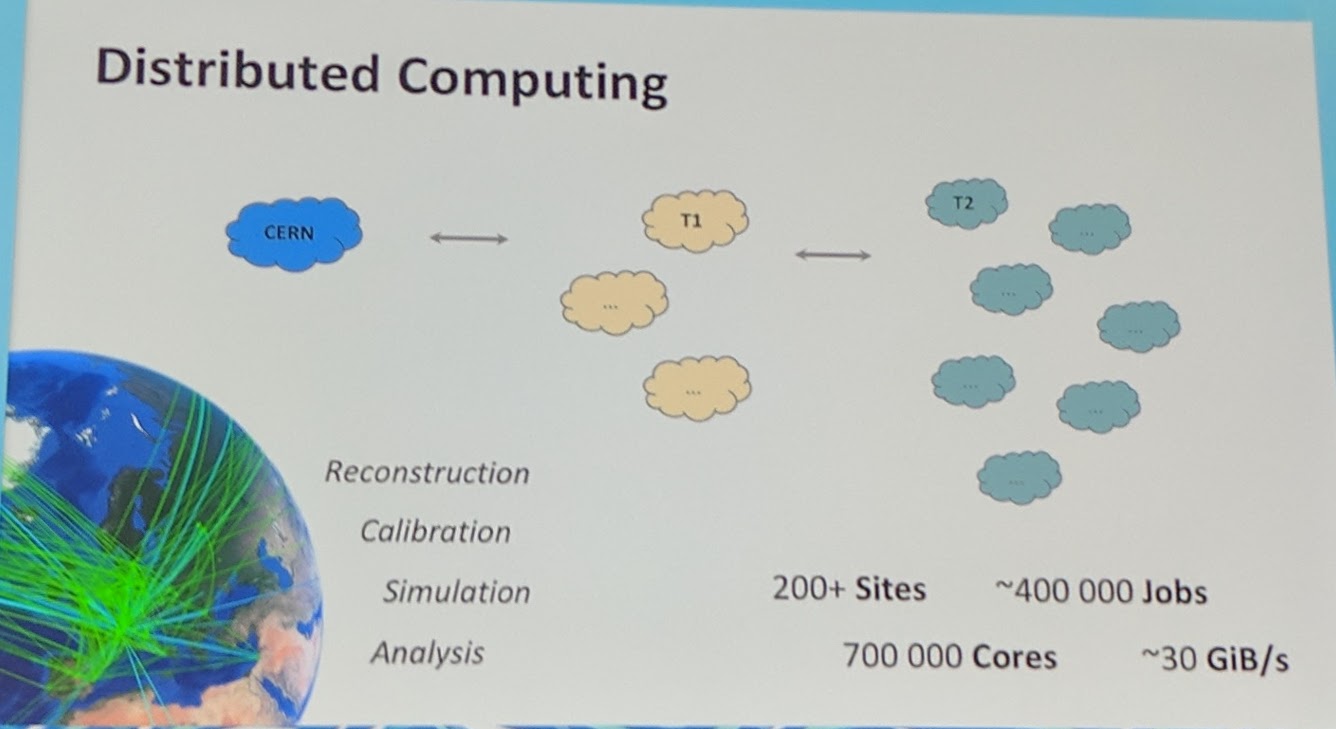
Through the federation new nodes can be added to any cluster at any time, and through a DaemonSet automatically pick up the work especially for a tool such as HTCondur which uses a node agent for it's own node registration.
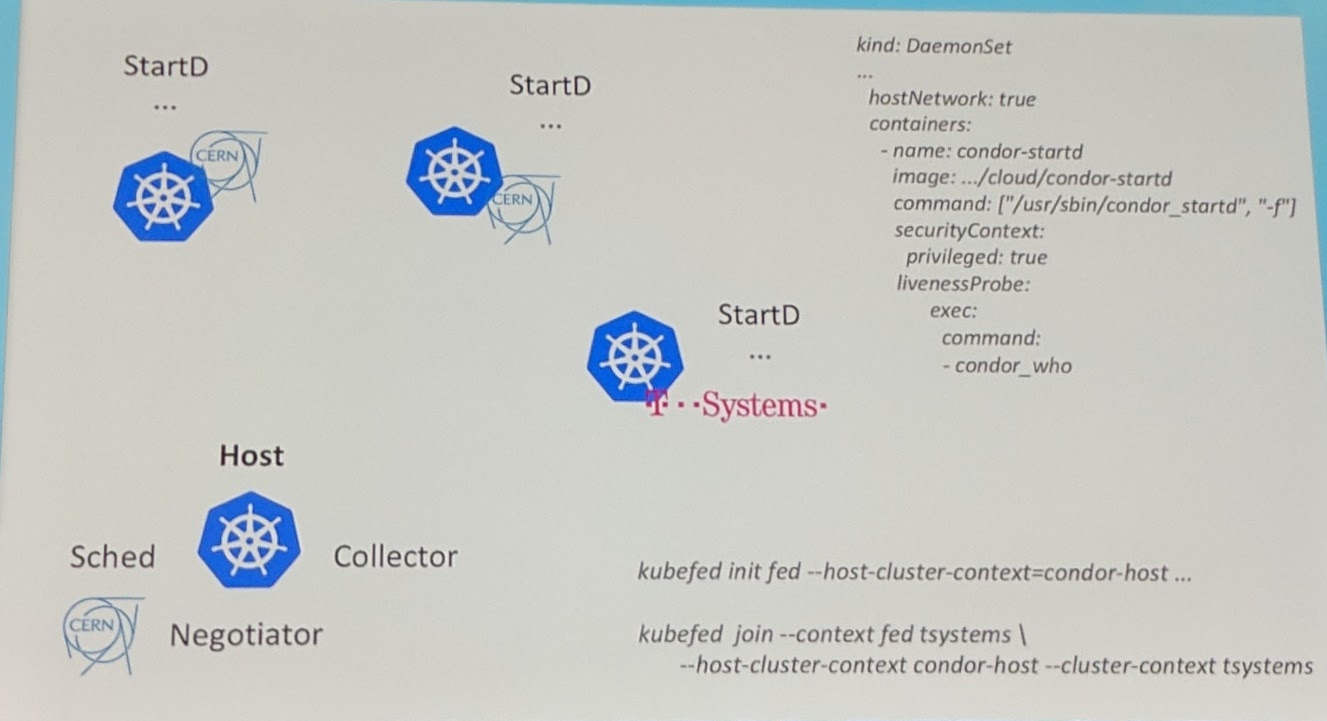
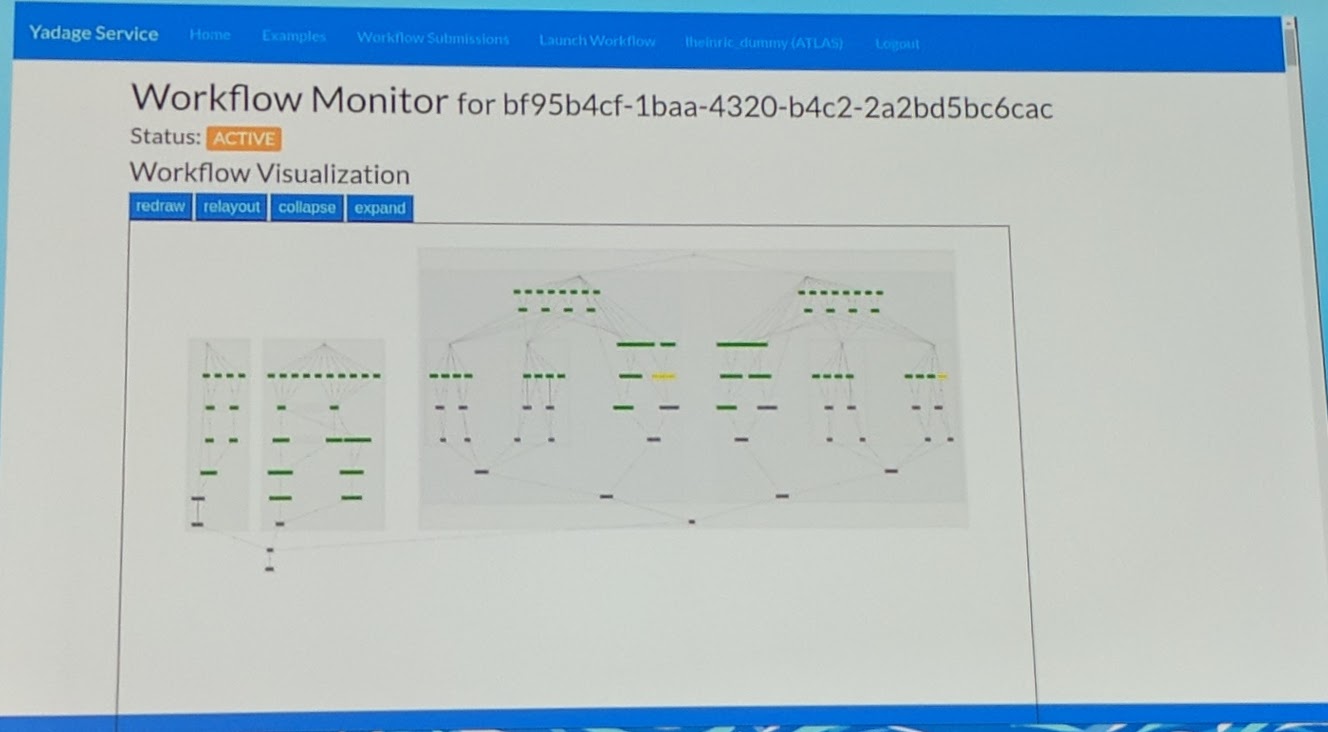
Their demo showed how to run complex jobs on multiple Kubernetes clusters with federation. For the visualization program, it can probably found here: GitHub recast-hep.
Keynote: From Innovation to Production - Dirk Hohndel, VP & Chief Open Source Officer, VMware
They created a product using open source.

"Innovation is done by individuals" - Dirk Hohndel
It is time to invest in minorities in the IT field. Opportunities need to be created for them.
Keynote: CNCF 20-20 Vision - Alexis Richardson, Founder & CEO, Weaveworks

CNCF until now was kind of in a "start up" phase as a company. Which now more and more moves to getting "Acceptance".
"We are not a start up any more" - Alexis Richardson

"For a lot of people 'cloud native' is just 'cloud'" - Alexis Richardson
Today it is pretty easy to install a project such as Hadoop for data analysis or TensorFlow for machine learning with KubeFlow in Kubernetes.
Deploying faster allows for a higher velocity of applications/products (lower Time To Market).

Everybody can do this faster and faster with CNCF projects.

"Just run my code" - Alexis Richardson
It shouldn't be run my applicatiom/container anymore, it should just be as simple as git pushing the code and automatically pushed out to your platform, e.g. Kubernetes.

Code centric by using git as the central point for the code and as the trigger for CI + CD.

"What is missing? The developers."
Ethics are more and more important with the greater tools which given even greater power.
 Ethics are more important than ever (looking at you Zuckerberg).
Ethics are more important than ever (looking at you Zuckerberg).
Talks
Replacing NGINX with Envoy in a Traffic Control System - Mark McBride, Turbine Labs, Inc (Advanced Skill Level)
A point for Envoy is that it is more made for a cloud native environment that changes fast.
NGINX does not have a great amount of routing options besides location and redirect. The routing in Envoy can be more dynamic, it is more made to route on facts besides the URI and/or server name which NGINX is mostly used for. It can possibly route on "fact" is this QA or Live? Which application version?
Envoy has taken notice of the already pretty good reload functionality and does it more dynamically.
Together with the overall dynamic in the routing, it is much more sophisticated than NGINX. Still to keep in mind, most software has good reason to co-exist beside each other depending on the task it should suffice in.
A good amount of big companies are maintainers on the project. To that over 50% of commits were made by people outside those companies.
Envoy is not reaching the current benchmarks looking at NGINX (and other webservers), but Envoy gives you more dynamic for a little bit less performance. A company has to look into the features, like filtering, of Envoy and the trade off, less performance, in comparison to the other existing solutions.
Migrations need to have enough people knowing what is going on and how to roll it back in case of failure. To that a list of points that need to watched out for during the rollout (e.g. latencies) should be made and a list of tasks to be done for the actual "piece by piece" rollout.
"Know when to roll back..." - Mark McBride
Health checks from their perspective are only good for "Yes, I'm listening on that port/accepting requests" and not is the application "working" (e.g. successfully processing requests/data).
They are looking into open sourcing applications that can speed up own migrations.
I'd recommend to checkout the recording of the talk as there is a good amount of Envoy stuff and overall how one would roll this out explained.

Rook Project Intro – Bassam Tabbara, Tony Allen & Jared Watts, Upbound (Any Skill Level)
Rook takes the load of managing storage backends in Kubernetes of your shoulders.
It solves the limitations of each cloud providers having it's own storage aka vendor locking with the cloud. Rook runs the storage ON the Kubernetes cluster which allows stateful workload to be moved more consistently between different clouds because the storage configuration stays the same. With the storage configuration staying the same on each cloud, Rook has created a working abstraction between different clouds.

With the upcoming support for CockroachDB and Minio, this will even further move to decouple certain applications from each cloud providers.
Rook uses the same patterns as for example CoreOS's etcd-operator or their prometheus-operator. Rook goes beyond that with managing/operating each storage "backend" to a certain aspect to as written take the load of the shoulders of the user.

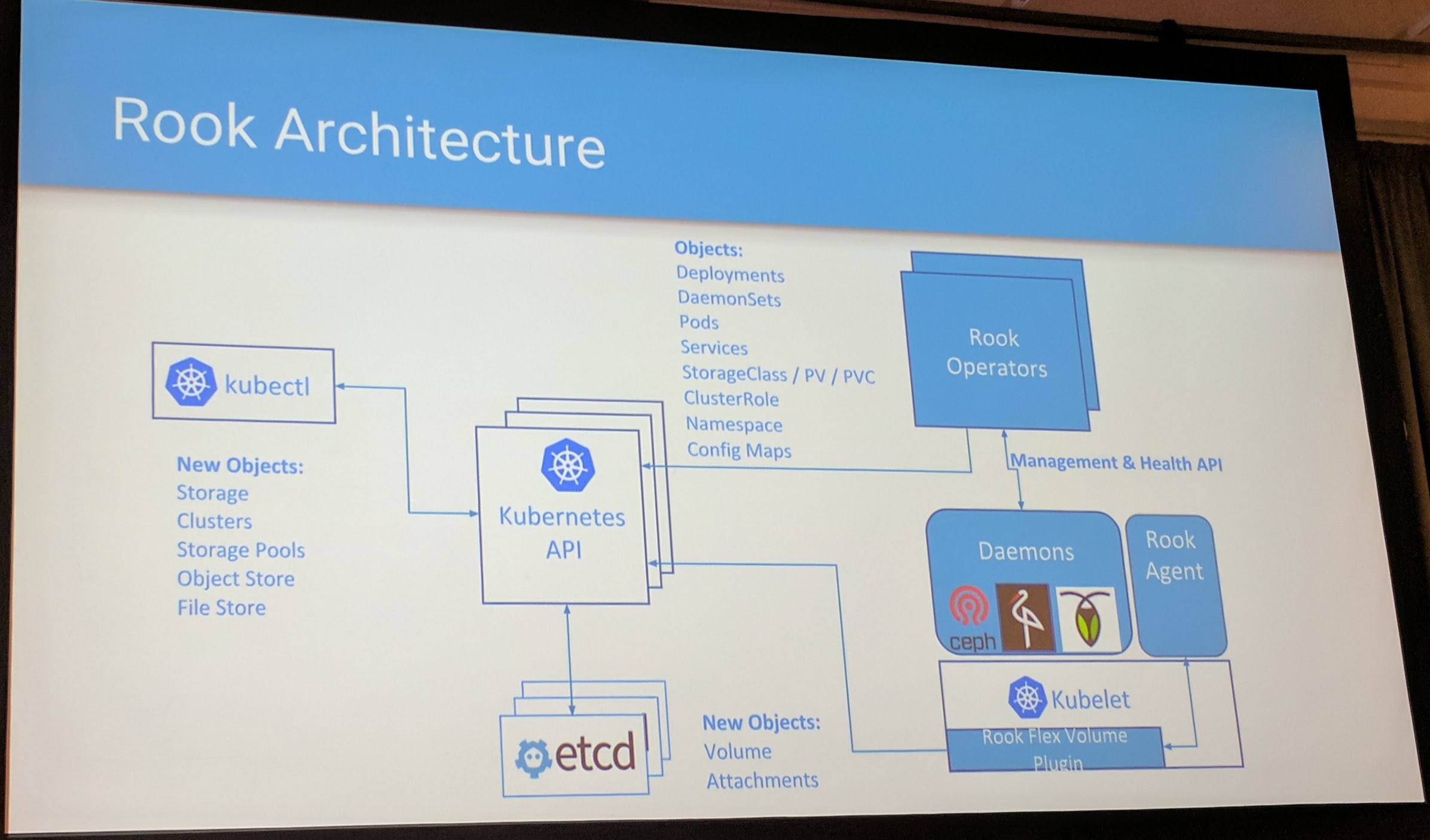
In point of managing/operating, the Rook operator makes sure the cluster is healthy and also provisions the storage for the storage.
Rook tries to be more of a framework for storage solutions, next to Ceph there will be as mentioned soon be support for CockroachDB, Minio, Nexenta Storage and more. It allows current storage providers to simply integrate with Rook and let it do the "dirty" work. This is good as some storage providers can with that "move" the workload to the community to implement and possibly add best practices to health checks.
In the demo he went through the quickstart guide and showed an example with WordPress which used block storage.
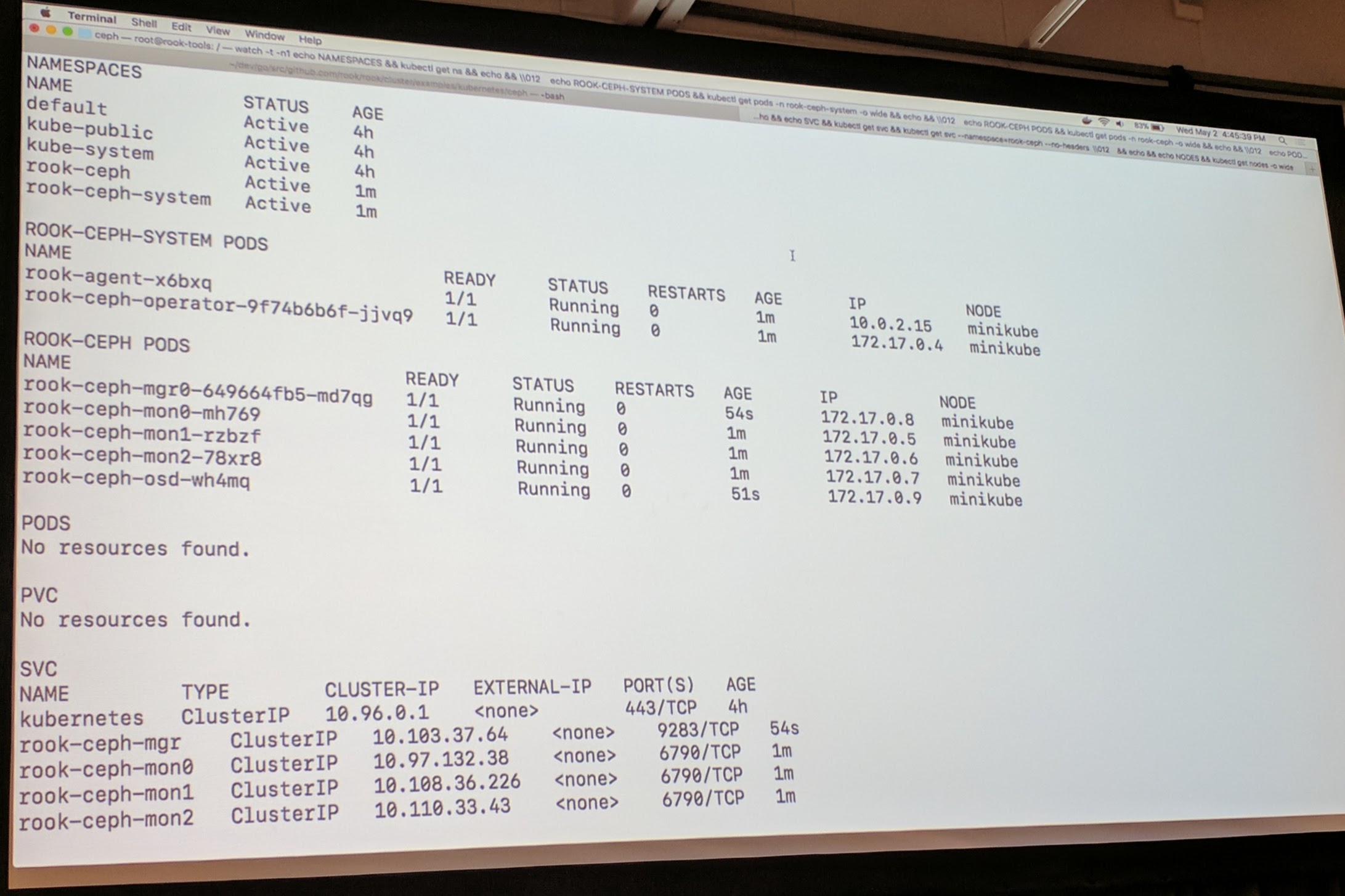
The cluster is now ready to be used after maybe 20-45 seconds.
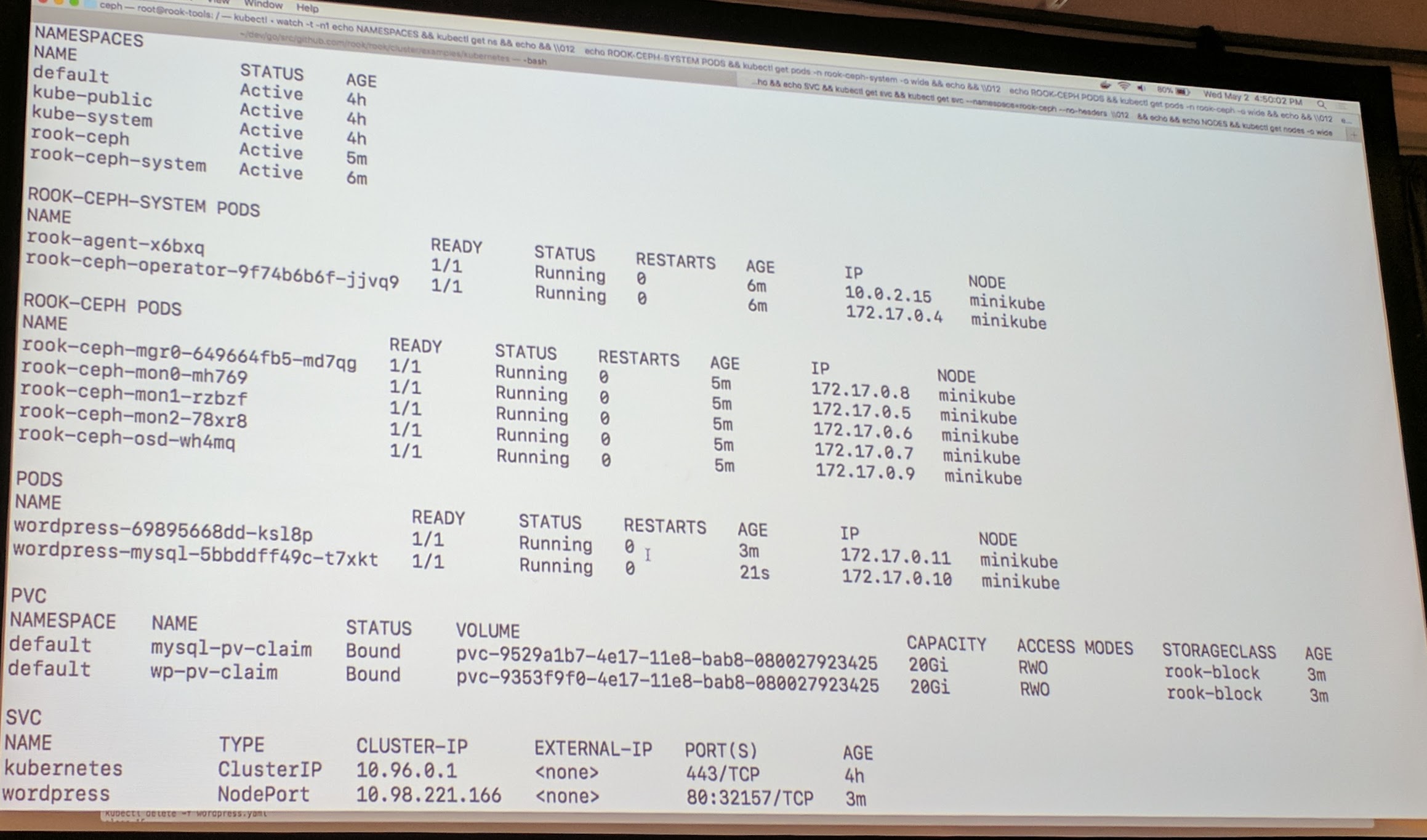
Killing the MySQL pod didn't cause issues, because Kubernetes brought a new one and Rook agent made sure that it is only used after the other one is terminated (fencing).
That is it for the intro, if you want to know more checkout Rook.io.

Evening Keynotes
Keynote: Anatomy of a Production Kubernetes Outage - Oliver Beattie, Head of Engineering, Monzo Bank
NOTE I have not been to this keynotes. Just listing it here for completeness.
Keynote: Container-Native Dev-and-ops Experience: It's Getting Easier, Fast. - Ralph Squillace, Principal PM – Azure Container Platform, Microsoft
NOTE I have not been to this keynotes. Just listing it here for completeness.
Keynote: Cloud Native Observability & Security from Google Cloud - Craig Box, Staff Developer Advocate, Google
NOTE I have not been to this keynotes. Just listing it here for completeness.
Keynote: CNCF End User Awards - Presented by Chris Aniszczyk, COO, Cloud Native Computing Foundation
NOTE I have not been to this keynotes. Just listing it here for completeness.
Keynote: Prometheus 2.0 – The Next Scale of Cloud Native Monitoring - Fabian Reinartz, Software Engineer, Google
They have more than 15000 stars on GitHub. The first version was cut in March 2014, later on in January 2015 Prometheus was publicly announced.
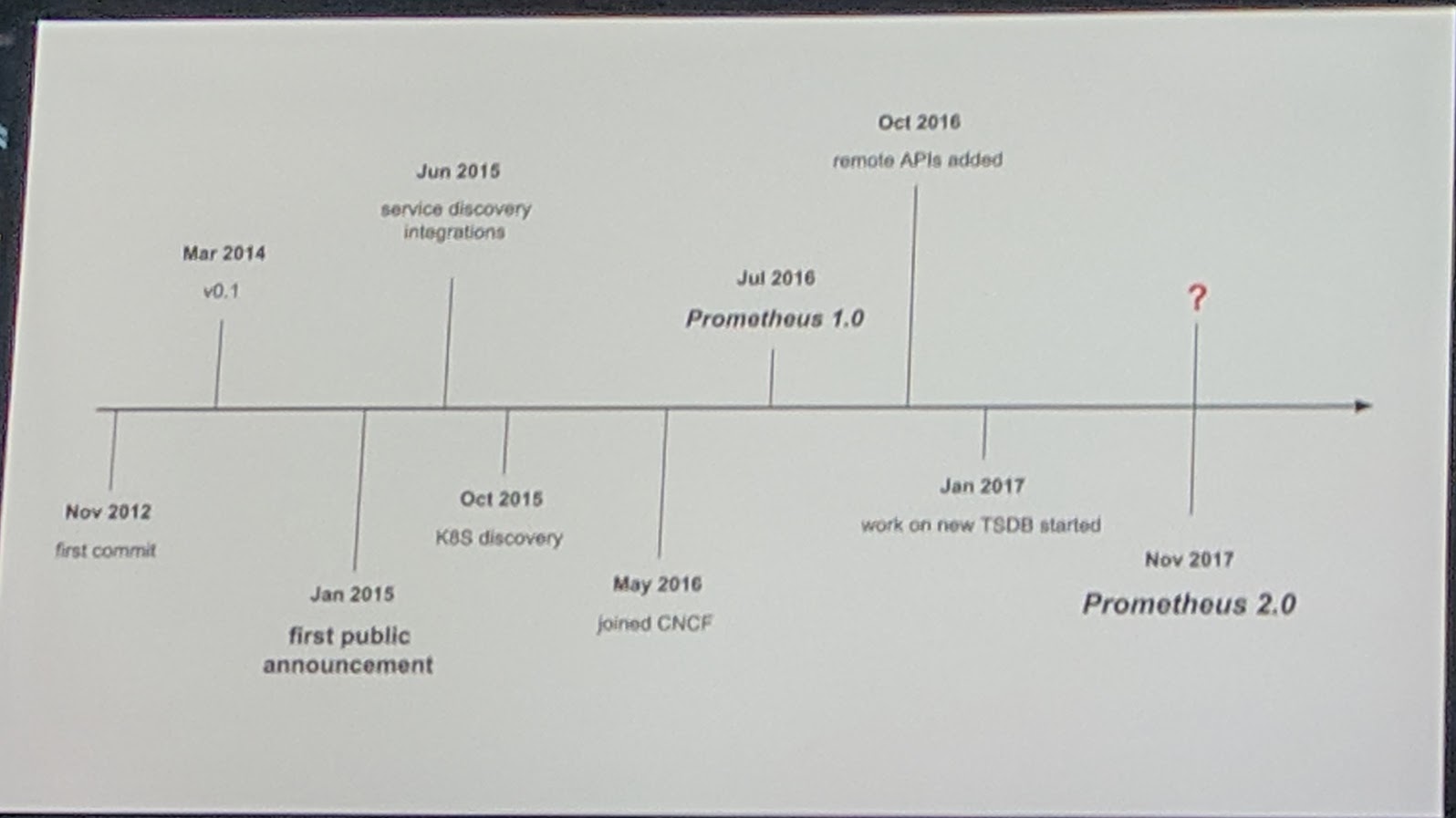
For the Prometheus 2.0, they created a new TSDB engine for it as others wouldn't perform fast enough. "Can persist 1.000.000+ samples/core/sec to disk"
After they optimized the TSDB, they noticed that all load was going outside the DB, especially the scrapping part of Prometheus.
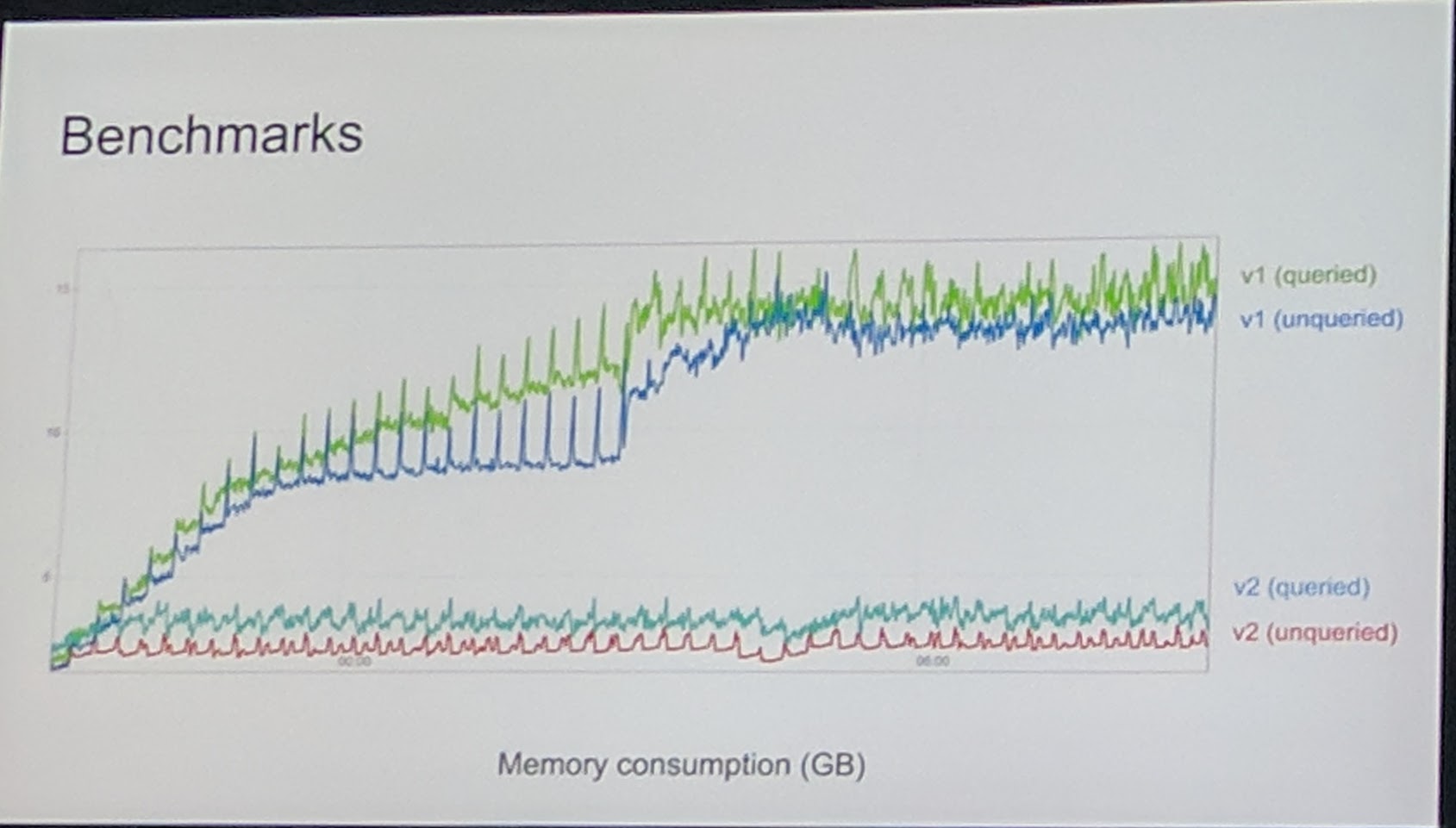
With Prometheus 1.0 you would need to wait for weeks to see if the resources you gave it is enough.
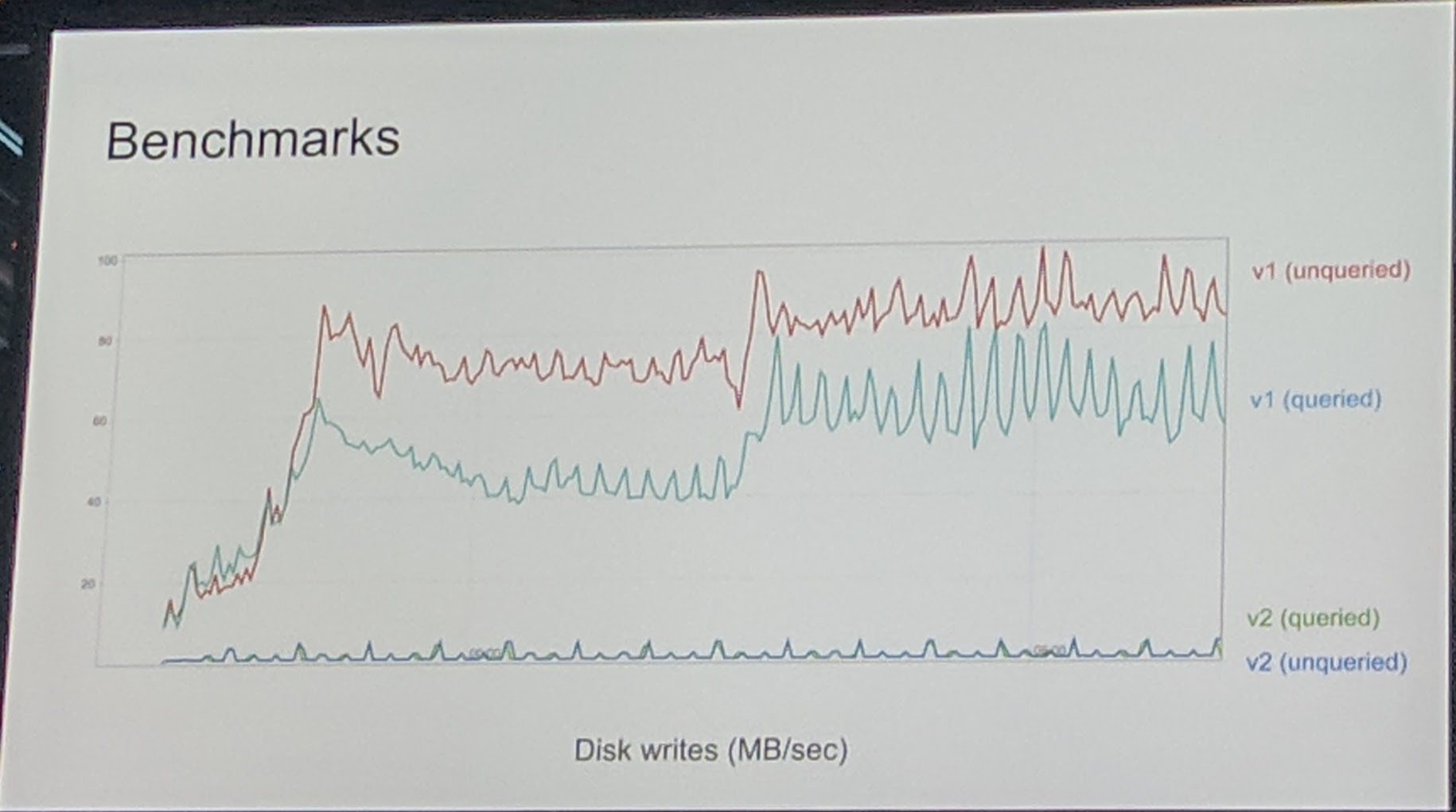
With Prometheus 2 they also massively increased the query latency which was getting more and more with Prometheus 1.
Staleness has also been improved in Prometheus 2. These improvements made the alerting more agile due to the faster triggering of "missing" data.
They want to stay engaged with OpenMetrics.

There is a book available "Prometheus Up & Running" and free for the next 30 days for KubeCon goers.
Keynote: Serverless, Not So FaaS - Kelsey Hightower, Kubernetes Community Member, Google
"That's where I come in and steal your servers" - Kelsey Hightwoer

"Don't standardize all events. The envelope is enough" - Kelsey Hightower
A standardized event envelope can be found here.
Keynote: Closing Remarks - Liz Rice, Technology Evangelist, Aqua Security

"Just follow the smell of sponsors" - Liz Rice
Summary
Thanks for the beer CNCF and KubeCon!

It was nice meeting a lot of new people and people from Rook Slack in person.
Have Fun!