
Running ownCloud in Kubernetes with Rook Ceph Storage - Part 1
This a cross post of a post I wrote for the ownCloud Blog, the original post can be found here: Running ownCloud in Kubernetes With Rook Ceph Storage.
Thanks to them for allowing me to write and publish the post on their blog!
In dieser zweiteiligen Artikelreihe wird es darum gehen ownCloud hochverfügbar in Kubernetes zu betreiben.
Der erste Teil wird dabei auf die Grundaspekte und Requirements eingehen, so das am Ende ein Plan bereit ist der im zweiten Teil dann Schritt für Schritt umgesetzt wird.
Zusammengefasst soll folgendes erreicht werden:
- Hardware-/ Serverausfälle sollen nicht zu:
- Datenverlust führen.
- ownCloud an sich nicht mehr verfügbar ist.
- Steigende Userzahlen sollen weniger/ keine Probleme verursachen:
- Ceph ist an sich je nach gegebenen Storage in den genutzten Servern schnell unterwegs und sollte ohne Probleme mit vielen Usern klar kommen.
- Die Datenbank ist neben dem Storage noch ein denkbares "Bottleneck", jedoch komnmt das darauf an wie und welche Features in ownCloud genutzt werden.
Kubernetes - Was ist das?
Kubernetes ist ein Orchestrator für Container. Bedeutet das Kubernetes Container verteilt über mehrere Server laufen lassen kann und noch weitere Features die uns dann nützlich sein werden. Neben Container laufen lassen, kann Kubernetes noch vieles mehr, unteranderem mit Leichtigkeit HTTP Anwendungen im Internet erreichbar zu machen. Dafür wird das Kubernetes Ingress Feature genutzt.
Im weiteren Kontext der Artikelreihe wird Kubernetes (Grund-) Wissen vorrausgesetz. Sollte Kubernetes noch eine "Pandorasbüchse" für sie sein, kann dies unteranderem durch die hervorragenden Tutorials auf der Kubernetes Homepage Stück für Stück aufgebaut werden, siehe Tutorials - Kubernetes.
ACHTUNG Der zweite Artikel in der Artikelreihe geht davon aus das ein funktionierendes Kubernetes Cluster mit einem Node/ Worker mindestens vorhanden ist.
Was brauchen wir dafür?
Fangen wir erstmal bei den Komponenten an die immger gebraucht werden an und arbeiten uns dann direkt auch zu entsprechenden Tools/ Projekten vor die uns im Kubernetes Umfeld dabei helfen können.
Datenbank - PostgreSQL
Fangen wir bei einer der wichtigsten Komponenten an, die Datenbank.
Im Falle von kleinen ownCloud Instanz, kann es sein das SQLite als Datenbank eingesetzt wird. SQLite ist nicht für Hochverfügbarkeit gemacht. Es sollte in jedem Fall ein Wechsel auf gegebenfalls PostgreSQL, MySQL oder Oracle in betracht gezogen werden. Oracle Datenbank Server Unterstützung ist in der ownCloud Enterprise Edition verfügbar. Für mehr Informationen was SQLite angeht, siehe When to and not to use SQLITE - FAQ - ownCloud Central.
Unter den unterstützten Datenbanken, ownCloud Documentation 10.1 - Database configuration on Linux, ist unteranderem PostgreSQL. Da es recht einfache Operator in Kubernetes gibt die ein PostgreSQL Cluster laufen lassen können, werden wir diese nun nutzen.
Bevor jedoch der "PostgreSQL Operator" gezeigt wird, was ist so ein Operator überhaupt?
Ein Operator in Kubernetes vereinfacht gesehen ein Automatisierungsmechanismus. Anhand von Custom Objekten in Kubernetes, sogenannten CustomResourceDefinitions, reagiert der Operator darauf und erstellt in den meisten Fällen entsprechende Objekte in Kubernetes.
Bedeutet als Beispiel für einen PostgreSQL Operator: Wenn ein PostgreSQL Objekt erstellt wird, reagiert der Operator darauf und erstellt automatisch Stück für Stück Kubernetes Objekte (e.g., Service, Deployment, StatefulSet) um ein PostgreSQL Cluster zu erstellen.
In diesem Artikel wird Zalando's Postgres Operator zum Einsatz kommen, um ein PostgreSQL cluster in Kubernetes zu betreiben.
Storage
ownCloud braucht Storage um die hochgeladenen Dateien zu speichern. Die Datenbank braucht auch einen Speicher (Storage) für, e.g., User Logins.
Für Owncloud macht ein Filesystem Storage, als bekanntestes Beispiel NFS, am meisten Sinn. Grund für Nutzung eines Filesystem Storage anstatt Block Storage ist, dass Block Storage nicht wirklich für mehr als einen Writer gemacht ist. Man kann auch Object Storage, bekannte Beispiele AWS S3, in ownCloud einbinden, jedoch "beschränken" wir uns in dieser Artikelreihe auf die Nutzung des Filesystem Storage für ownCloud.
Für PostgreSQL sollte zwingend Block Storage verwendet werden, da es dort sonst zu Performanceeinbusen kommt. Hintergrund der Performanceeinbusen ist, dass bei Block Storage kann die Datenbank "direkter" schreiben. Dabei kann der Linux Kernel entsprechend Caching betreiben.
Nun da die Frage geklärt ist welcher Storage Typ für die verschiedenen Komponenten zu nutzen ist, gehen wir über zum Einsatz kommenden Storage Software.
Ceph
Das Ceph Projekt existiert seit ungefähr 2006. Ceph hat als oberste Priorität Datensicherheit. Das passt perfekt, da wir keine unserer wertvollen Daten, e.g., Urlaubsfotos, Musik oder ähnliches, verlieren möchten.
Man muss sich auch keine Sorgen machen das Ceph so schnell nicht mehr weiterentwickelt wird. Die Ceph Foundation unterstützt Ceph zentral, um die starke Entwicklung noch stärker als sie schon ist voran zu treiben. Das zeigt Mal wieder wie gut es ist wenn Firmen die Open Source nutzen "zusammen kommen" und gemeinsam an einem Strang ziehen.
Ceph an sich ist sehr komplex, bringt dafür aber auch einiges an Features mit sich. Neben Filesystem storage, gibt es auch Block storage und sogar Object Storage in verschiedenen Protokollen (e.g., S3 kompatibles Protokoll, OpenStack SWIFT). Was ich grundlegend empfehlen würde ist, sich durch das Intro to Ceph - Ceph Documentation durch zulesen um die Grundkonzepte zu verstehen. CERN, Deutsche Telekom, und viele andere Organistationen und Firmen nutzen Ceph als Storage System für ihre Applikationen.
Wahrscheinlich kommt jetzt die Frage auf "Wo soll Ceph laufen?". Das ist eine gute Frage die jedoch schnell beantwortet ist, in Kubernetes. Rook.io ist der Weg das zu schaffen.
Rook ermöglicht es Ceph und andere Software für persistente Datenhaltung, wie z.B. EdgeFS, Minio, CockroachDB und weitere, in Kubernetes laufen zu lassen.
Beim Punkt Datenbank - PostgreSQL wurden Kubernetes Operatoren angesprochen. Rook ist genau auch ein Operator, der auf die Custom Kubernetes Objekte reagiert und dann zum Beispiel bei CephCluster Objekten ein Ceph Cluster in Kubernetes Stück für Stück startet.
Neben des Erstellen des Ceph Clusters, kümmert sich Rook momentan auch um das erstellen und löschen von Volumen in Ceph, damit auch das "Management" der passenden PersistentVolume Objekt in Kubernetes.
Für Container und Kubernetes Interessierte kann ich empfehlen sich in die Themen Kubernetes Blog - Container Storage Interface (CSI) und Kubernetes - Persistent Volumes einzulesen.
Damit haben wir also den Punkt Storage für ownCloud in Kubernetes geklärt. Fehlt nur noch eine Komponente, Redis.
Redis
Standardmäßig wird die Datenbank für "File Locking" eingesetzt. Jedoch ist das eine entsprechende Last die am Ende eher störend für die Datenbank ist, deswegen werden wir Redis dafür einsetzen. Zu diesem Thema gibt es ownCloud - Transactional File Locking
Dafür wird auch wieder ein Operator eingesetzt, der uns das Leben dabei entsprechend einfacher machen soll. kubed Operator kann unteranderem Redis als Cluster in Kubernetes laufen lassen.
Für mehr Informationen zum Redis Part im kubed Operator, siehe Redis Documentation - kubedb Operator.
Der Plan
Um eine Übersicht zu geben wie das in Kubernetes aussehen wird, hier ein Diagram mit dem "Geflecht" aus Komponenten:
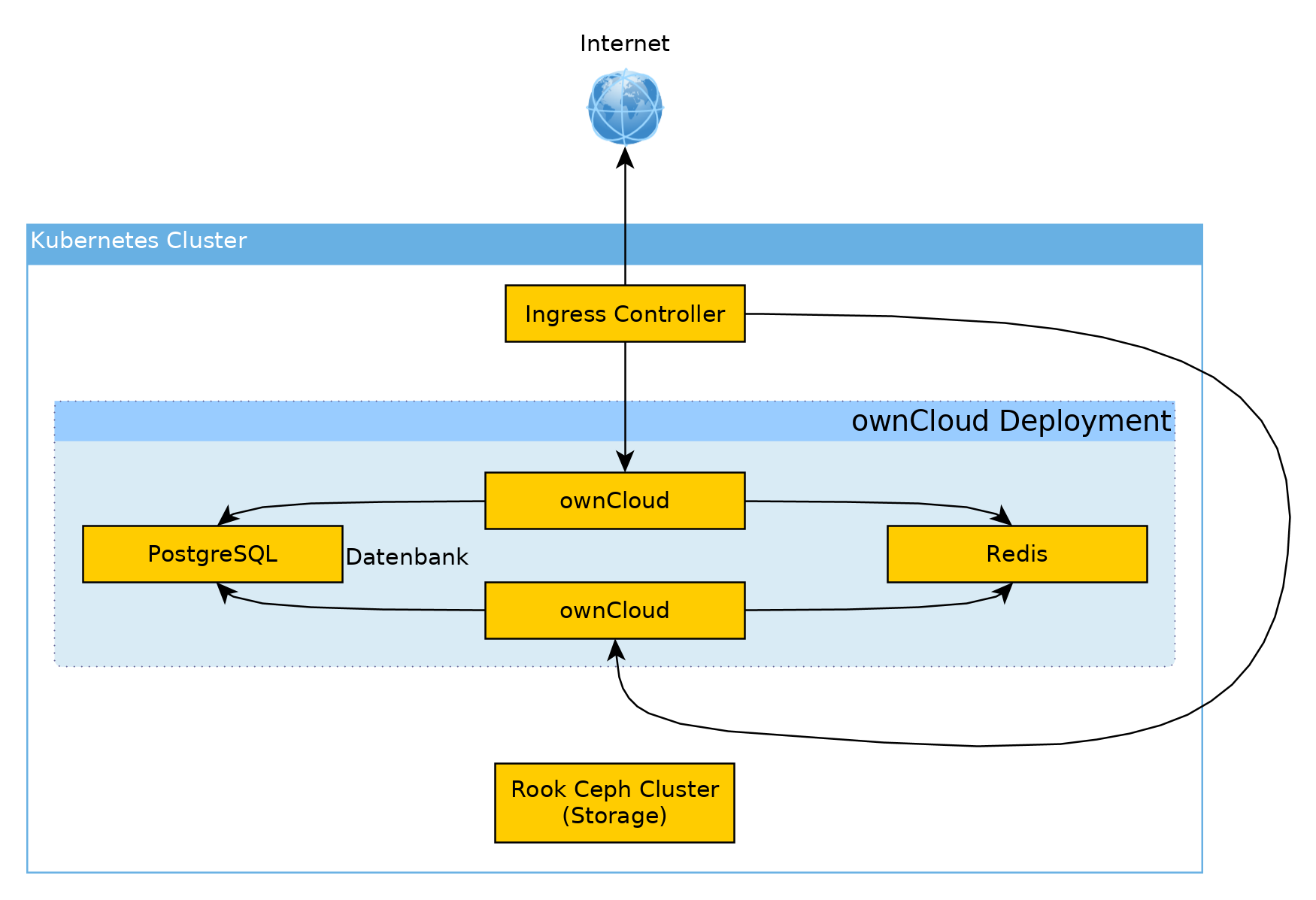
Um das ganze nochmal in Stichpunkten zusammenzufassen:
- Kubernetes um ownCloud und die anderen Komponenten als Container laufen zu lassen.
- Ingress Controller (hängt von der Kubernetes Installation ab) um ownCloud im Internet verfügbar zu machen.
- Zalando's Postgres Operator für PostgreSQL Cluster in Kubernetes.
- kubed Operator für Redis Cluster in Kubernetes.
- Ceph als Storage und per Rook.io als Container in Kubernetes.
Das ist der Plan und der Plan wird im zweiten Teil der Artikelreihe, Schritt für Schritt umgesetzt um ownCloud in Kubernetes redundant und ausfallsicher laufen zu lassen.